


【2026年版】SEOとは?初心者向けに具体例や事例を紹介
SEO対策
最終更新日:2026.07.01
![]()
Webサイトの規模が大きくなってくると、どうしてもテーマの似たようなページやコンテンツの重複したページが生成されてしまいますが、そこの管理・対応はしっかりとできているでしょうか。
重複コンテンツに対して何も対処せず放置しておくと、検索エンジンから高い評価を受けられないばかりか、最悪の場合、ペナルティを受けて検索順位が大幅に下落するなど、SEOへ悪影響を及ぼす場合があります。
本記事の内容をご参考に、Webサイトの状況を把握し、重複コンテンツに対して適切な処置をするようにしてください。
SEO対策にお困りではありませんか?
SEO対策で成果を出すには、実績のある支援会社を選ぶことが大前提。PLAN-Bは、SEO事業歴19年・継続率95.3%のSEOコンサルティングサービスを持つ会社です。
※弊社「SEOコンサルティングサービス」を1ヶ月を超える契約期間でご契約のお客様が対象
※集計期間(2024/01~2024/12)中に月額最大金額を20万円以上でご契約のお客様(当社お客様の87%は月額最大金額が20万円以上)が対象
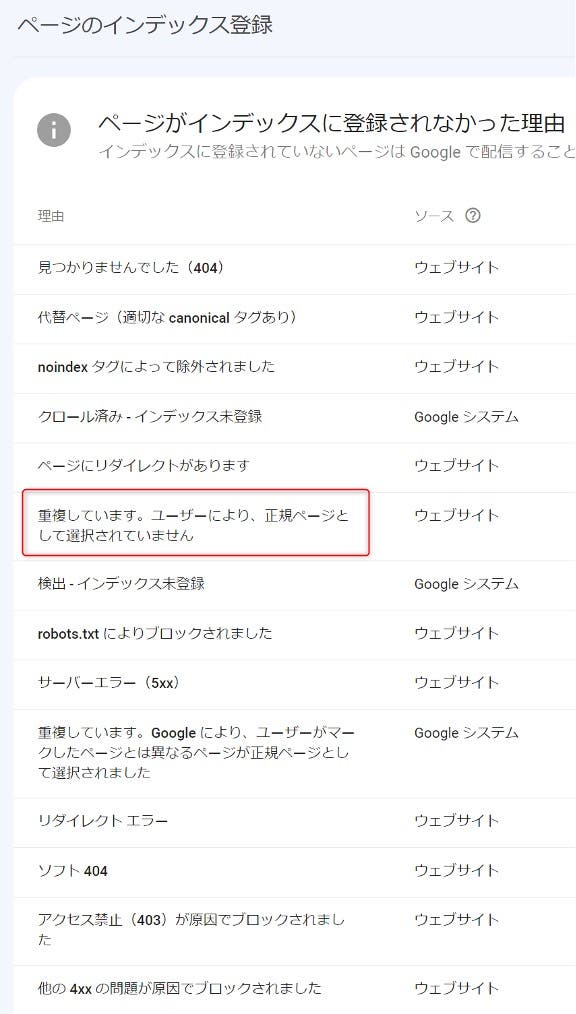
Google Search Consoleでインデックス登録状況を見てみると、「重複しています。ユーザーにより、正規ページとして選択されていません」と表示されることがあります。
これはそのコンテンツが「他のコンテンツと同じ、または類似している」ことを意味しています。つまり、重複コンテンツとして認識されているということです。
重複コンテンツがWebサイト上にあること自体は、Googleのスパムポリシー違反にはなりませんが、あまりに多すぎるとユーザビリティを損ねる可能性があります。Googleはユーザビリティをランキング要因としているため、もし重複コンテンツが存在しているなら、なぜ重複コンテンツが発生しているのか原因を究明し、対策を打つことが大切です。
サイト上で重複コンテンツが発生することは通常のことであり、Google のスパムに関するポリシーの違反にはなりません。ただし、同一のコンテンツが多数の異なる URL からアクセスできるようになっていると、ユーザー エクスペリエンスの悪化につながることがあります(たとえば、どれが正しいページなのか、2 つのページに違いがあるかどうかなどの疑問をユーザーが抱く可能性があります)。また、検索結果でのコンテンツのパフォーマンスを追跡することが難しくなる可能性もあります。
💡インデックス状態を確認する方法
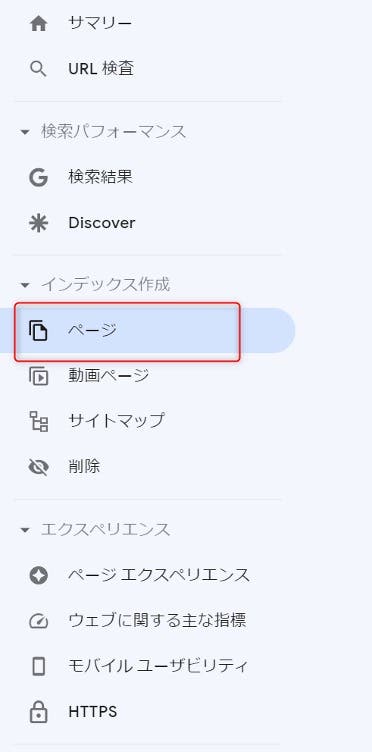
Googleサーチコンソールの左メニュー「インデックス作成」内の「ページ」をクリックすると、インデックスに登録済み、および未登録のページ数の推移をグラフで確認できる他、インデックス未登録であるページについては、登録されなかった理由の一覧を見ることができます。
さて、前述した「重複コンテンツ」について、もう少し細かく解説いたします。
Webサイト内の複数のページに同一のコンテンツ、あるいは酷似したコンテンツが存在している場合、それらは検索エンジンに「重複コンテンツ」と見なされます。「重複コンテンツ」と見なされてしまった場合、そのページは検索エンジンから高い評価を受けることはできず、また意図的に量産された悪質なページだと判断された場合は、逆にペナルティを受ける対象となってしまいます。
Googleの根本的な理念として、オリジナリティ(独自性)のあるコンテンツを高く評価する傾向にあります。そのため、Webサイト内の他のページ、あるいは他のWebサイトと酷似したコンテンツは必然的に低い評価対象となります。
もちろん内容の一部が被っている程度では、検索エンジンからペナルティを受けることはありません(もしそうであったら、インターネット上の大多数のページがペナルティの対象となってしまいます)。定量的な線引きは難しいのですが、複数の段落に渡って同じ文章がそのまま転用されていたり同じ図表が使い回されていたりする場合、ペナルティの対象となる可能性が高いです。
Webサイト内の複数ページで主義主張や思想が一貫しているのは悪いことではなく、むしろWebサイトのテーマが明確であるため検索エンジンに好まれる傾向にあります。問題となるのは、Webサイト内のページ数やコンテンツ量を水増しする意図で作為的にコンテンツを流用しているケースです。
Webサイト内に重複コンテンツが生成されてしまう要因は、
<1>コンテンツ管理の側面
<2>実装の側面
の大きく二種類に分けられます。
「<1>コンテンツ管理の側面」については、メディアサイトなどで時折見られますが、ページのコンテンツ量をかさ増しする意図で、Webサイト内の別ページのコンテンツの一部を新規ページにそのまま流用してしまうケースです。 ※SEOの知見がない新人ライターさんなどが、より丁寧に文章を記述しようという思いから、悪気なくやってしまうケースもあるようです。
Webサイト内の別ページの内容を参照したい場合は、コンテンツをそのまま転用するのではなく、内部リンクを設置してユーザーが別ページに遷移できるようにしましょう。(内部リンクの設置は、SEO的にも良い効果があります)
もう一方の「<2>実装の側面」については、例えば、
などの原因により、内容は同一だがURLの異なるページが意図せず発生するケースです。
例えば、
(a) https://www.amazon.co.jp/
(b) https://amazon.co.jp/
この2つのページは、開いていただくと分かりますがどちらも同一のページに飛びます(bのページを開いた場合、301リダイレクトという処理が行なわれ、aのページに自動的に遷移します)。
これがもし、aのURLとbのURLどちらもアクセスできてしまう場合、検索エンジンから見ると、同じ内容のページが異なるURLで複数存在していることになります。後述しますが、検索エンジンは基本的に同一のページがWeb上に複数存在することを好まず、高い評価を受けることができません (ユーザーの視点で考えても、似通ったページが複数存在するWebサイトは分かりづらく、良い印象を受けません)。
amazonの例のように、同一の内容であるページ間には301リダイレクトや、後述する「canonicalタグ」を実装し、どれか一つのURL(「正規ページ」と呼びます)のみに検索エンジンの評価を集中させるようにしましょう。
「正規ページ」についても詳しくご紹介します。
前提として、Googleの基本的な思想は「検索キーワードに対して最適な回答を提示すること」であり、もっと噛み砕いて言えば、「この検索キーワードが来たら、このWebサイトのこのページを検索結果に表示させよう」という対応関係をあらかじめ整理してデータベースに格納しています。
コンテンツ重複とは、例えばAという検索キーワードに対し、Webサイト内のページBとページCがどちらも回答になりえてしまう状況です。これは上述のGoogleの理念に反しており、SEOの観点では避けるべきです(この状態は、ページBとページCで検索キーワードAを奪い合っている、すなわち「カニバリゼーション」と表現されることもあります)。
このような状態を回避し、ひとつの検索キーワードに対してひとつのページのみマッチングする状態が理想と言えます。とはいえWebサイトの運用上、重複コンテンツを完全にゼロにすることができず、複数のページに同一のコンテンツが存在せざるを得ないケースもあるかと思います。
そこで登場するのが、「canonical」と呼ばれるHTMLタグです。
具体的な使い方は次項にて詳しくお伝えしますが、概要としては「canonicalタグ」を用いることで、どのページが正規ページなのかを検索エンジンに伝えることができます。これにより、コンテンツ重複によるマイナスの影響を抑えることができます。
では、具体的に「canonicalタグ」を用いて正規ページを指定する方法についてご紹介します。例として、コンテンツ内容が重複した「ページX」「ページY」「ページZ」の3つが存在すると仮定します。
HTMLタグの実装に入る前に、まずは「どのページを正規ページとするか?」を検討します。「最もコンテンツが充実しており、検索ユーザーへ提供できる価値が最も高いページはどれか」という観点で考えるのが良いかと思います。「canonicalタグ」によって、想定通りに正規ページを検索エンジンが認識してくれたら、それ以外のページは基本的に、検索結果に露出されなくなります。ですので、検索結果に出したい最良の1ページを選定するべきです。
さて、検討の結果、「ページX」を正規ページにするとします。この場合、「ページY」および「ページZ」のHTML内に「ページXが正規ページだよ」というシグナル(信号)を検索エンジンに伝えるためのタグを埋め込むことになります。
具体的には、
<link rel=”canonical” href=”(ページXのURL)”>
という形式のタグを埋め込みます。例えば、ページXのURLが
https://www.plan-b.co.jp/example/
であった場合、
<link rel=”canonical” href=” https://www.plan-b.co.jp/example/” >
のように記述します。記述場所は、HTMLのheadタグ内、すなわち、<head>~</head> で囲われた内部にしてください。
このように、「canonicalタグ」を用いて正規ページを設定し、検索エンジンからの評価を正規ページに集中させることを、SEOの文脈で「正規化」と言ったりもします。
注意点として、「canonicalタグ」を実装したからといって、必ずしも検索エンジンが正規ページをこちらの想定通りに認識してくれるとは限りません。「canonicalタグ」の実装は、言ってみれば「このページを正規ページとしてくれたら嬉しいです」というリクエストを検索エンジンに送っているにすぎず、どのページが正規ページになるか、あるいはそもそも正規化が行われるかどうかは、最終的には検索エンジンの判断に委ねられてしまいます。
「canonicalタグ」や「正規化」についてはこちらの記事でも分かりやすく解説していますので、ぜひ併せてご覧ください。
さて、canonicalタグの実装により、想定通りに正規化が行われたかどうかは、Googleサーチコンソールにて確認できます。左メニュー「URL検査」にて、正規ページ以外のページ(先の例で言うページYとページZ)のURLを入力して検査を実行します。
ここで、想定通りに正規化が行われていた場合は、下図のように、
という記載を見ることができます。
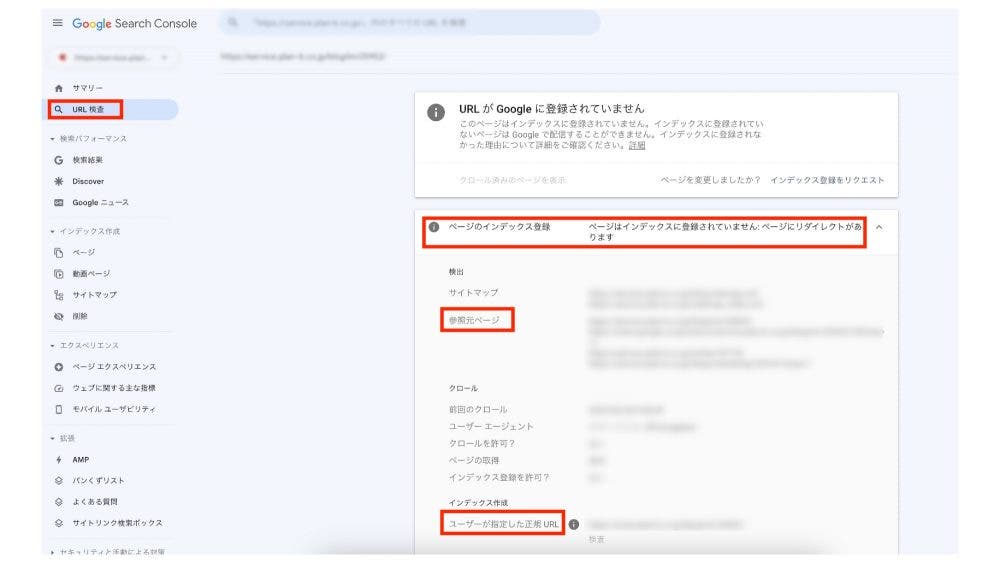
あるいは、左メニュー「インデックス作成」内の「ページ」にて、
「代替ページ(適切な canonical タグあり)」の項目を選択します。ここには、canonicalタグによって別ページを正規ページに指定しているページ(すなわち、先の例で言うページYとページZ)が列挙されています。
正規化を実施したページが、列挙されているページの中にあれば、canonicalタグによるシグナルが検索エンジンに正しく伝わっていると言えます。
重複コンテンツを避けるべき理由や、重複コンテンツの発生要因、canonicalタグを用いた回避策についてご紹介しましたが、いかがでしたでしょうか。Webサイトの規模が大きくなってくると、重複コンテンツを完全にゼロにすることは非常に難しいので、問題点を理解した上で適切に対処することが必要です。
リソースを投下して制作したWebページが、重複コンテンツが原因で検索エンジンから低い評価を受けてしまっては非常にもったいないですので、本記事の内容をご参考に、重複コンテンツと上手に付き合うようにしてみてください。
■株式会社PLAN-Bについて
SEO対策やインターネット広告運用などデジタルマーケティング全般を支援しています。マーケティングパートナーとして、お客様の課題や目標に合わせた最適な施策をご提案し、「ビジネスの拡大」に貢献します。
■SEOサービスについて
①SEOコンサルティング
SEO事業歴19年以上、SEOコンサルティングサービス継続率94.9%※の実績に基づき、単なるSEO会社ではなく、SEOに強いマーケティングカンパニーとして、お客様の事業貢献に向き合います。
②SEOツール「SEARCH WRITE」
「SEARCH WRITE」は、知識を問わず使いやすいSEOツールです。SEOで必要な分析から施策実行・成果振り返りまでが簡単に行える設計になっています。
■その他
関連するサービスとしてWebサイト制作や記事制作、CROコンサルティング(CV改善サービス)なども承っております。また、当メディア「PINTO!」では、SEO最新情報やSEO専門家コラムも発信中。ぜひ、SEO情報の収集にお役立てください。
※弊社「SEO/LLMOコンサルティングサービス」を1ヶ月を超える契約期間でご契約のお客様が対象
※集計期間(2025/01~2025/12)中に月額最大金額を20万円以上でご契約のお客様(当社お客様の87%は月額最大金額が20万円以上)が対象


発生頻度の高いエラーコードへの対処法や、その他ステータスコードの意味について解説します!
■資料内容
・エラーコードとは?
・よくあるエラーとその対処法
・ステータスコード一覧
・SEO守りの施策と攻めの施策
突然のエラーにお困りの場合や、ステータスコードの意味を学んでおきたいという方はぜひダウンロードしてみてください!
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。
share

2022年にPLAN-Bに中途入社。入社前はフリーランスとして雑誌編集やwebメディアのライティング、YouTube動画のディレクションなどに携わっていた。現在はPLAN-Bのマーケティング部で「PINTO!」の記事編集を担当している。

SEO対策
最終更新日:2026.07.01

SEO対策
最終更新日:2025.07.29

SEO対策
最終更新日:2023.10.30

SEO対策
最終更新日:2026.04.17

SEO対策
最終更新日:2026.04.21

SEO対策
最終更新日:2023.09.15

SEO対策
最終更新日:2024.04.24

SEO対策
最終更新日:2025.07.29