
【2026年版】SEOとは?初心者向けに具体例や事例を紹介
SEO対策
最終更新日:2026.03.02
![]()
更新日:2025.07.29

クローラビリティとは、検索エンジンのクローラーがどれだけWebページを見つけやすい状態であるかを示す言葉です。
クローラーに認識されなければ検索結果に表示されずユーザーにも届かないため、クローラビリティを高めることはSEOにおいてとても重要です。
このページでは、クローラーにページを発見してもらいやすくするための具体的な施策を学びます。
クローラビリティを改善する施策は、次の2つの観点から考えると全体像を把握しやすくなります。
なお、これらの施策を実施するには技術的な知識が必要なケースもあるため、必要に応じてエンジニアと相談しながら進めてください。
まずはクローラーにWebサイトやWebページの存在を確実に伝えるためにできる施策を見ていきましょう。
通常、クローラーはインターネット上のリンクを辿ってページを発見しますが、自ら働きかけることで、より早期にクローラーに認識してもらうことが可能です。
具体的には、Google Search Consoleからインデックス登録リクエストを送信します。手順はこれまでも紹介していますが、改めて以下にまとめています。
インデックス登録リクエストを送信する手順
①Google Search Consoleにログインし左メニュー「URL検査」をクリックし、上部の検索バーに登録したいURLを入力する
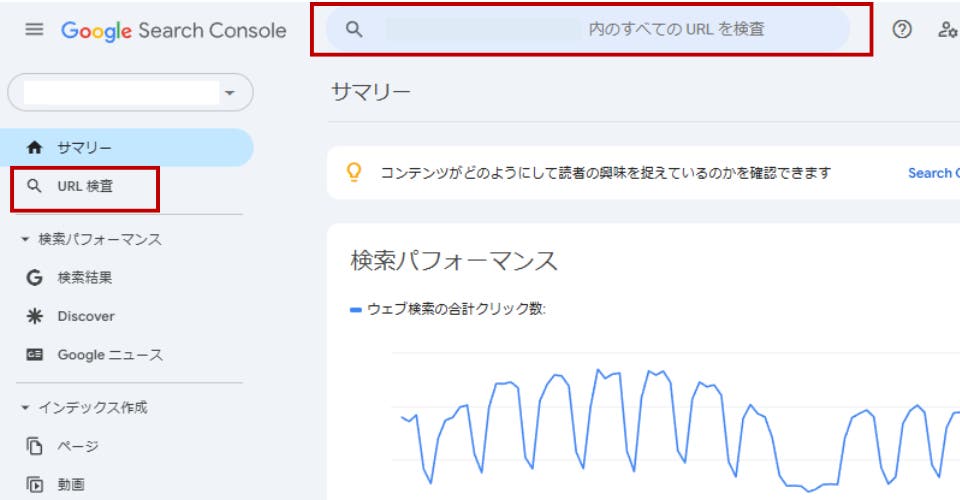
②図の右下にある「インデックス登録をリクエスト」をクリックすれば、申請完了です。通常、数時間〜数日でクローラーが回ってきます。
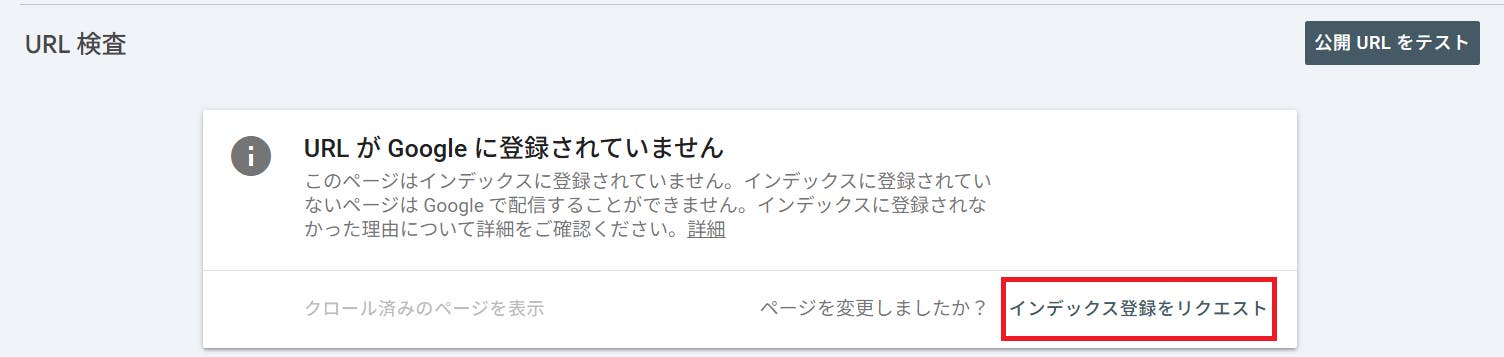
①で紹介した方法は、ページ単位のクロールを促すものです。Webサイト全体をクローラーに認識させるには、XMLサイトマップが活用できます。
XMLサイトマップとは、サイト内のURLや更新日、更新頻度などの情報が書かれたXML形式のファイルのことです。WordPressを利用している場合、プラグインを利用することで簡単に作成できます。
代表的なWordPressのプラグインと手順
1.Yoast SEO
①プラグインをインストール&有効化
②メニューバーの[Yoast SEO] > [一般] > [サイトの機能] から「XMLサイトマップ」を有効にする
③[XML サイトマップを表示]から、生成されたXMLサイトマップのURLが確認できます
①プラグインをインストール&有効化
②[サイトマップ] >[一般的なサイトマップ]から「サイトマップを有効化」にチェックする
③[サイトマップを開く]から、生成されたXMLサイトマップのURLが確認できます
作成が完了したら、Google Search ConsoleからXMLサイトマップのURLを送信しましょう。
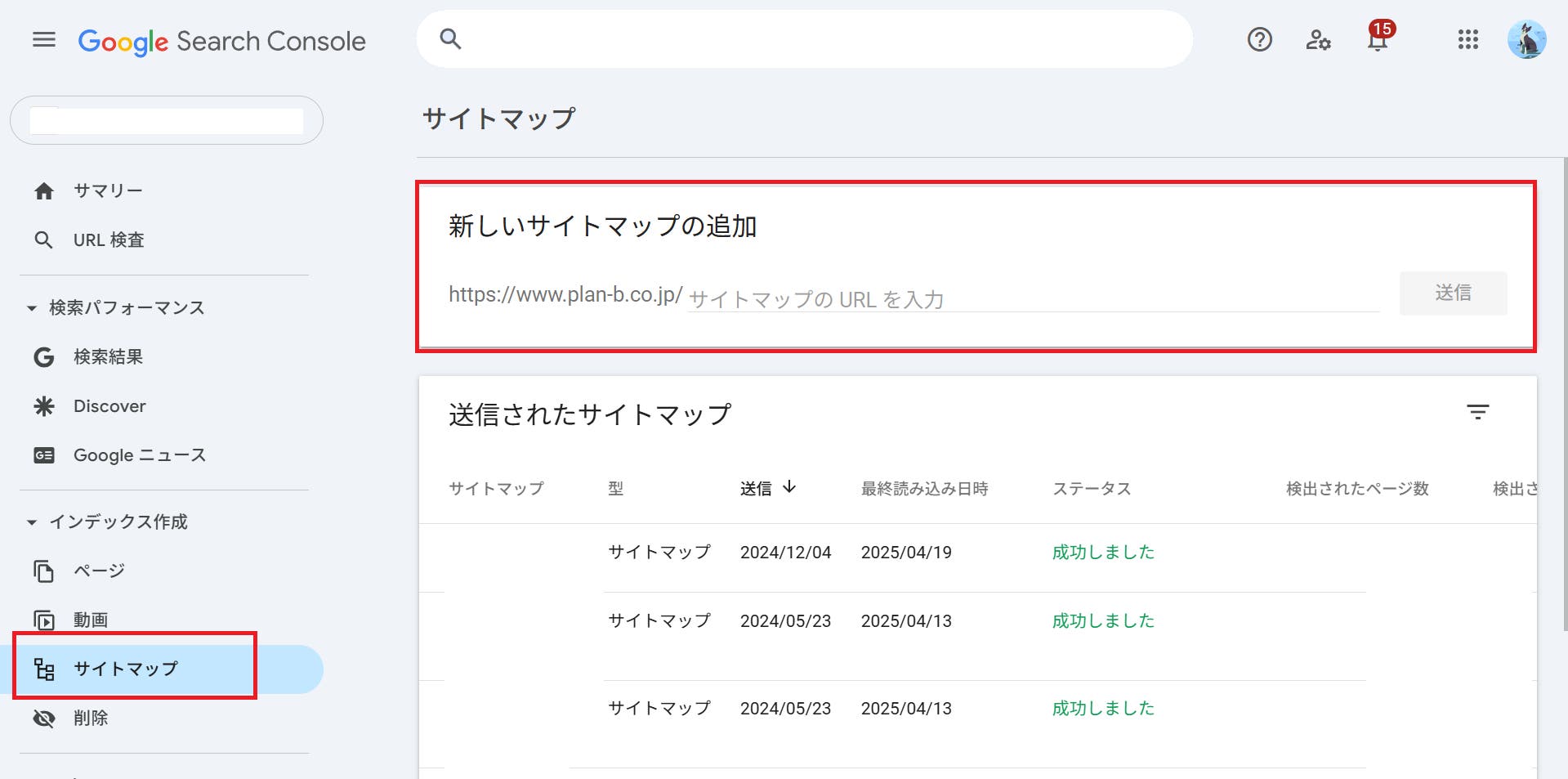
XMLサイトマップの送信手順
メニューバーの[サイトマップ]をクリックし、「新しいサイトマップの追加」から取得したURLを送信して完了です。
特にページ数が多いサイトでは、XMLサイトマップでサイトで巡回を促しても、クローラーが巡回しきれないケースがあります。そのため、検索エンジンがサイト内の情報を効率よくクロールできるような工夫も必要です。
パンくずリストとは、ページがサイト全体のどこに位置しているのかを階層的に示すナビゲーションのことです。
パンくずリストを設置することで、Googleなどの検索エンジンがサイトのディレクトリ構造やカテゴリの関係性を把握しやすくなることに加え、カテゴリページへの内部リンクとしても機能するため、クローラーがサイト内を効率的に巡回しやすくなります。
設置場所に決まりはありませんが、ユーザーの利便性を考慮してページの上部に設置するケースが多いです。
なお、パンくずリストを設置する際は、検索エンジンの理解をより促進させるために構造化データも併せて追加しましょう。
💡構造化データとは?
構造化データとは、検索エンジンにページの内容を正確に伝えるために記述する、標準化されたデータ形式のことです。
そのコンテンツに書かれている内容の意味や役割をあらかじめ決められた形式に合わせて記述することで、検索エンジンがそのページ内容を正しく理解しやすくなります。
構造化データにはさまざまな種類がありますが、パンくずリストの構造化データを例に見てみましょう。
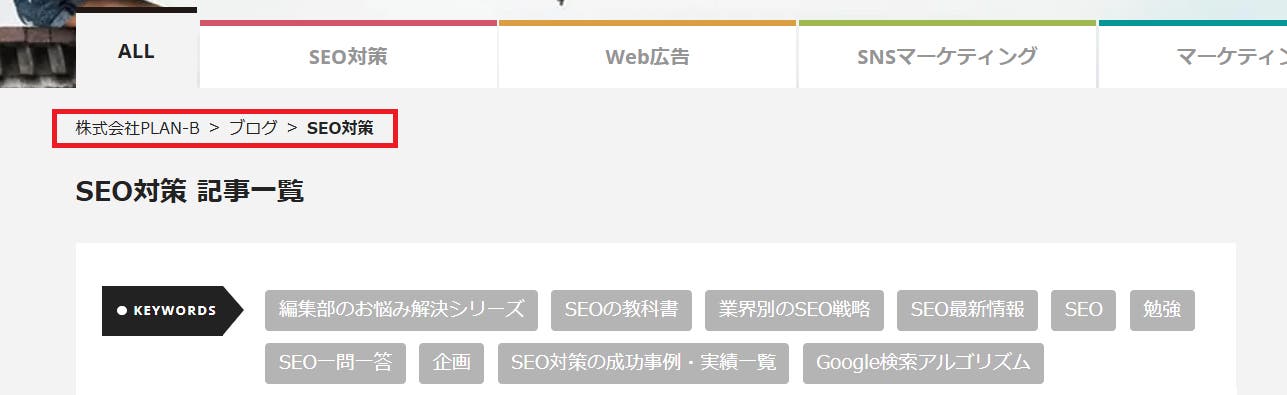
例えば、当メディアPINTO!の中カテゴリーページ「SEO対策」(URL:https://www.plan-b.co.jp/blog/seo/)の場合、該当ページの階層構造は次のようになっており、
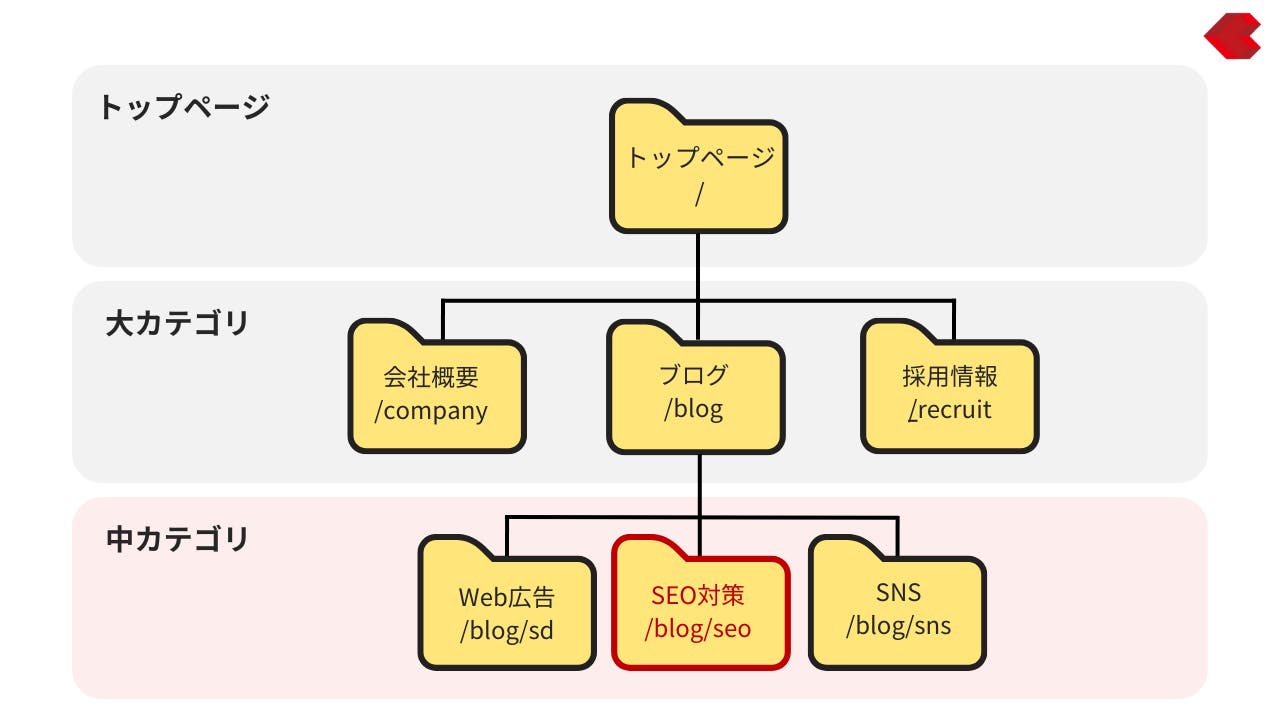
この場合、以下のようなパンくずリストの構造化データを記述します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
json <script type="application/ld+json"> { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "ホーム", "item": "https://www.plan-b.co.jp/" }, { "@type": "ListItem", "position": 2, "name": "ブログ", "item": "https://www.plan-b.co.jp/blog/" }, { "@type": "ListItem", "position": 3, "name": "SEO対策", "item": "https://www.plan-b.co.jp/blog/seo/" } ] } </script> |
詳しくは、次のステップ「検索エンジンに正しく評価されるためにすること」で学ぶので、ここでは、パンくずリストと構造化データは一緒に設定するもの、くらいの理解で十分です。細かな仕様まで把握していなくても問題ありません。
関連記事:パンくずリストの効果的な設置方法
関連コンテンツへの内部リンクを設置することで、検索エンジンのクローラーがサイト内を効率よく巡回できるようになります。特に、階層の深いページはクローラーが回ってきにくい傾向があるため、内部リンクは有効な施策です。
内部リンクを設置する時は、以下のポイントを押さえましょう。ユーザーが求める情報にスムーズにたどり着けるリンクを張ることがポイントです。
例えば、「SEO対策の全体像」を解説する記事では、コンテンツSEOや内部対策についても触れることになります。そこで、あまり詳しい施策まで書きすぎると、「まずは全体像をざっくり把握したい」というユーザーにとっては情報が多すぎるかもしれません。
このようなケースでは、「コンテンツSEOについて詳しくはこちら」といった形で、ユーザーの理解度や関心に合わせた内部リンクを設置します。
また、Googleなどの検索エンジンは、内部リンクが多いページを重要なページとして認識していることにも留意しましょう。つまり、ページがクローラーに認識されても、内部リンクがなければそのページには価値がないと判断されてしまう可能性があるということです。こうした観点からも、内部リンクはとても重要な施策といえます。
意図せず公開されてしまったディレクトリや、テスト環境などのクロールさせる必要がないページに対しては、クロールを制御することでクロールする必要のあるページへのクロールを集中させることができます。
クロールにはクロールバジェット※というサイト単位でのクロール上限があるのですが、Google検索セントラルによれば、中規模(URL数1万以上で日々更新がある)のサイトや、大規模(URL数100万以上で週次更新のある)のサイトは、このクロールバジェット管理の対象としています。
※クロールバジェット…検索エンジンのクローラーが、特定のサイトをクロールする際に使えるリソースの上限のこと。
対象サイトでは適切に管理をしないと、不要なページへのクロールがバジェットを圧迫し、本来クロールすべきページが巡回されにくくなる恐れがあるのです。クロールを制御するには、以下2つの方法があります。
robots.txtファイルは、クローラー向けの指示書のようなものです。しかし、リンクなどによってそのページが関連性が高いと判断された場合は、クロールされ、インデックスされるケースがあります(このケースでは、中身が読み込めないためURLのみが表示されます)。あくまでクロールへの指示に留まり絶対的なものではないのでご注意ください。同様にrobots.txtでインデックスの制御もできません。
そのため、「検索結果に絶対に表示させたくない」という場合は、より強制力の強い .htaccessファイルを使用しましょう。
💡注意点:インデックス済みページの扱いについて
すでにインデックスされてしまったページに対して、いきなりrobots.txtでブロックをかけると、Googleのクローラーが変更を認識できず、インデックス上に古い情報が残ってしまう可能性があります。
そのため、まずはnoindexで除外指示を出し、インデックスから外れたことを確認してからrobots.txtでクロールをブロックするのが望ましいステップです。
クローラーはHTTPステータスコードを基にページの状態を判断します。正しいレスポンスを返すことで、クロール効率やインデックスの精度向上に役立ちますので、各ページが返すステータスコードを定期的に確認・管理することが重要です。
💡HTTPステータスコードとは?
私たちがWebサイトを閲覧しようとしたとき、システム側では「閲覧したいというリクエストに対し、レスポンスを返す」という処理が行われています。
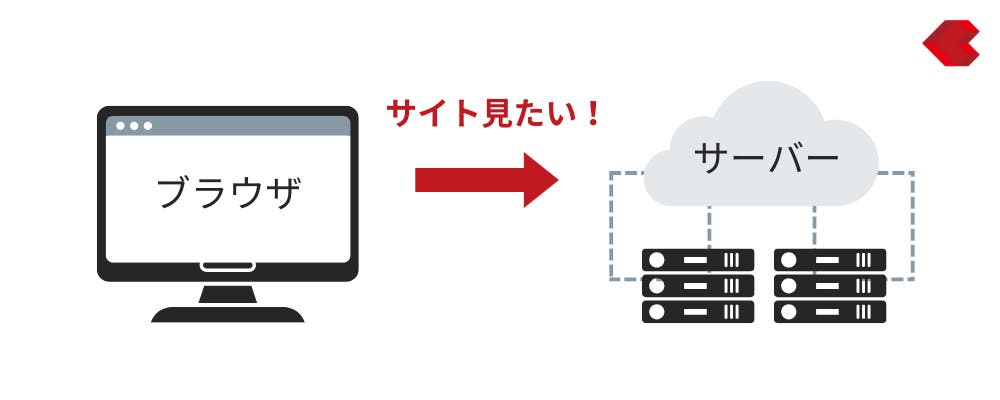
そのレスポンスを数字で返したものが「HTTPステータスコード」です。例えば400番台(403、404)のステータスコードは、処理の失敗を意味します。
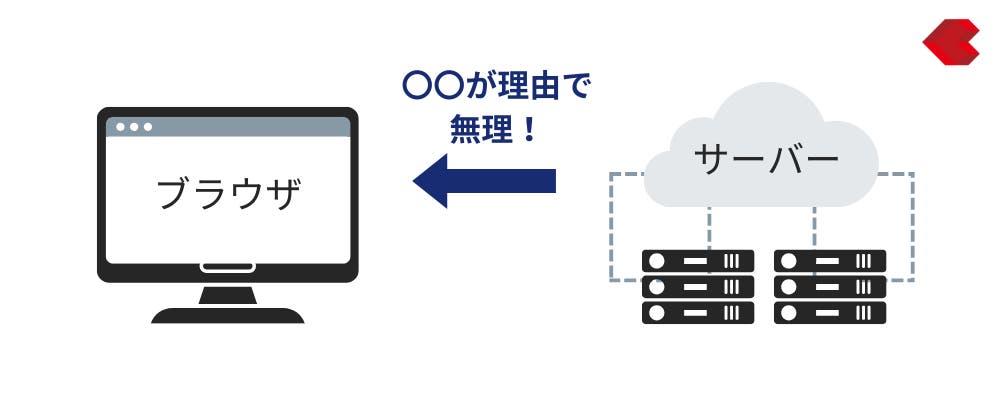
具体的には、以下の点を確認しましょう。
| 確認項目 | 正しいHTTPステータスコード |
| 存在しないページや、削除されている・公開されていないページがある場合、404ステータスコードを返しているか | 404 |
| ドメインやページの恒久的な移動によるURL変更がある場合、正しくクローラーに伝えられているか | 301 |
| 正常に表示されるページには200ステータスコードを返しているか | 200(200 OK) |
| ソフト404エラーが大量に発生していないか | 404または200(200 OK) ※詳しくは後述 |
特にクローラービリティの観点で注意したいのは、ソフト404エラーが大量に発生しているケースです。ソフト404エラーとは、200ステータスコードが返ってきているが、Googleは本来は404ステータスではないか?と判断しているものを指します。
ソフト404エラーは200のステータスコードを返すため、正常なページとしてクロールされます。そのため、本来クロールされなくてよいはずのページもクロールし、結果として、Webサイト全体のクロール効率の悪化に繋がる可能性があるのです。
対処方法は、次の通りです。
ソフト404エラーの発生状況は、Google Search Consoleから確認できます。
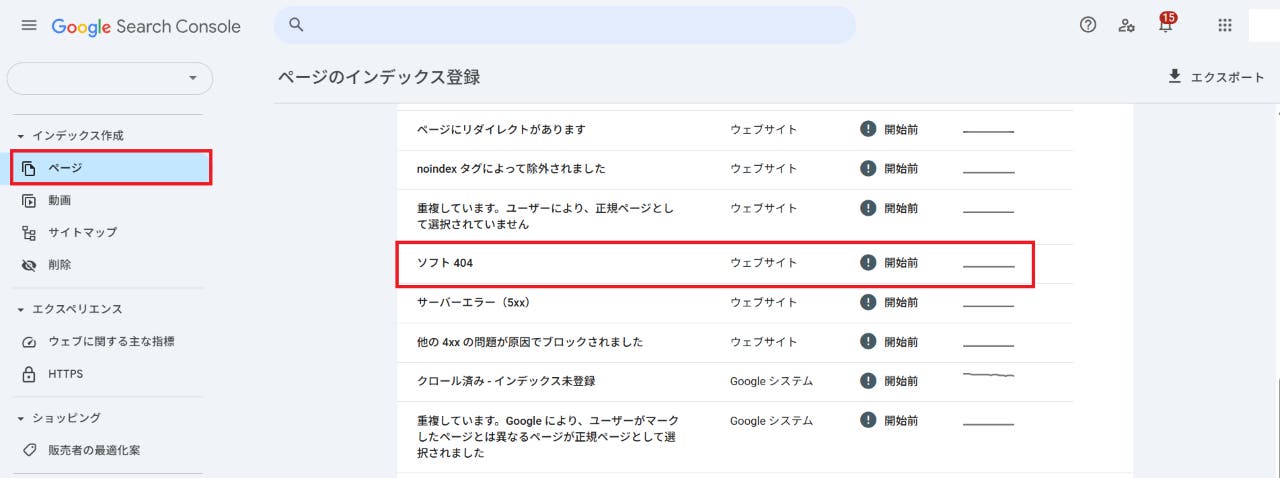
ソフト404の発生状況を確認する方法
①Google Search Consoleにログイン
②[インデックス作成]セクションにある[ページ]をクリックして、ソフト404の項目を確認します。
続いて、クローラーが回ってきても、クローラーが理解しづらい状態であれば、正しく評価してもらうことができません。次のステップでは、検索エンジンにWebサイトや各ページの内容を正確に伝え、適切に評価してもらうための施策について学んでいきます。

share

2017年よりオウンドメディアのSEO対策に携わる。新規メディアや新サービス立ち上げ時における、リード獲得を目的としたキーワード設計・コンテンツ作成・改善に強みがある。2024年3月にPLAN-Bに入社し、PINTO!のSEO対策を行っている。
SEO対策
最終更新日:2026.03.02

SEO対策
最終更新日:2025.12.25

SEO対策
最終更新日:2025.07.29

SEO対策
最終更新日:2025.07.29

SEO対策
最終更新日:2025.12.17

SEO対策
最終更新日:2026.03.02

SEO対策
最終更新日:2025.05.20

SEO対策
最終更新日:2026.02.27