
【2026年版】SEOとは?初心者向けに具体例や事例を紹介
SEO対策
最終更新日:2026.05.07
![]()
更新日:2025.07.29
構造化データとは、Webサイトの情報を検索エンジンに正確に伝えるための手段で、リッチリザルトの表示を促すなどSEOにおいて重要な役割を果たします。
本記事では構造化データの概要や非構造化データとの違い、マークアップの方法などを解説します。

※フォーム送信後、メールにて資料をお送りいたします。
専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
※フォーム送信後、メールにて資料をお送りいたします。

フォームでの問い合わせが
完了いたしました。
メールにて資料をお送りいたします。
構造化データとは、Webサイトのページ内容を検索エンジンが理解しやすいように標準化した、データ形式のことです。
例えばWebサイトに、以下のような情報が書かれているとします。
|
1 2 3 4 5 |
<div> Webサイト名:PINTO! 運営者:PLAN-B サイトアドレス:https://www.plan-b.co.jp/blog/ </div> |
人間はこの情報を見て
のように認識できますが、検索エンジンは同じように認識することができません。これを人間と同じように検索エンジンに認識してもらうために必要なのが、構造化データです。
構造化データは以下のように記述し、HTMLの<head>または<body>内に入れて使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "WebSite", "name": "PINTO!", "url": "https://www.plan-b.co.jp/blog/", "publisher": { "@type": "Organization", "name": "PLAN-B" } } </script> |
構造化データと非構造化データの違いは、検索エンジンなどの機械が意味まで理解できるように整理されているかどうかにあります。
構造化データは検索エンジンなどがわかるように、あらかじめ定められた形式やルールに従って整理されたデータです。
例としてWebサイトにおける記事やFAQなどを、検索エンジンが正しく理解できるようにコードにしたものが挙げられます。これによって、検索エンジンはWebページの内容を正確に理解しやすくなり、リッチリザルトの表示などにつながります。
※リッチリザルト…検索結果で通常のリンクと一緒に表示される、星評価・画像・FAQなどの追加情報。
一方、非構造化データは特定の形式に従っていない自由な形のデータです。
例えばメールの本文やSNSの投稿、画像、音声、動画などが挙げられます。これらのデータは人間には理解しやすいものの、検索エンジンなどの機械による処理は難しいです。
つまり、構造化データは「機械が処理しやすい情報」、非構造化データは「人間にとっては自然だが、機械には扱いづらい情報」であるといえます。
構造化データの活用によるSEOへのメリットとして、検索の多様化に対応しやすいことが挙げられます。
近年、検索スタイルが多様化しています。スマートスピーカーなどを使った音声検索やリッチリザルト、AI Overviewsなどがその代表例です。
※AI Overviews…Google検索で表示されるAIによる要約機能。
こうした変化に対応するには、ページの内容を検索エンジンが理解できる形式で伝えることが必要です。
例えばFAQページを構造化データでマークアップすれば、音声検索やリッチリザルトでその内容がピックアップされやすくなります。また商品情報や商品のレビューをマークアップすれば、価格や評価などの情報を検索結果に表示させやすくすることも可能です。
検索エンジンがWebサイトの内容を正確に理解しやすくなることも、SEOへのメリットの一つです。
Webページが構造化データでマークアップされていない場合、検索エンジンはWebページの内容を、HTMLの構造や文脈を元に推測しています。
しかし、それだけでは記事のタイトルや著者名などの正確な把握が難しいです。特に表記揺れがある、画像と本文が混在しているなど表現が多様な場合、検索エンジンが正確に意図を汲み取れないことがあります。
構造化データを実装すれば、「この要素はheadline(記事タイトル)です」「この部分はauthor(著者)です」というように検索エンジンが理解できる形式で伝えることが可能です。
これにより、検索エンジンは意味を持った情報として処理できるようになります。その結果、内容の誤認識や情報の取りこぼしが減り、検索結果において正確に適切な形で表示されやすくなります。
先ほど説明したように、リッチリザルトが表示されやすくなる点もSEOへのメリットの一つとして挙げられます。
リッチリザルトとは通常の検索結果に加えて、補足情報が以下のように表示されることを指します。
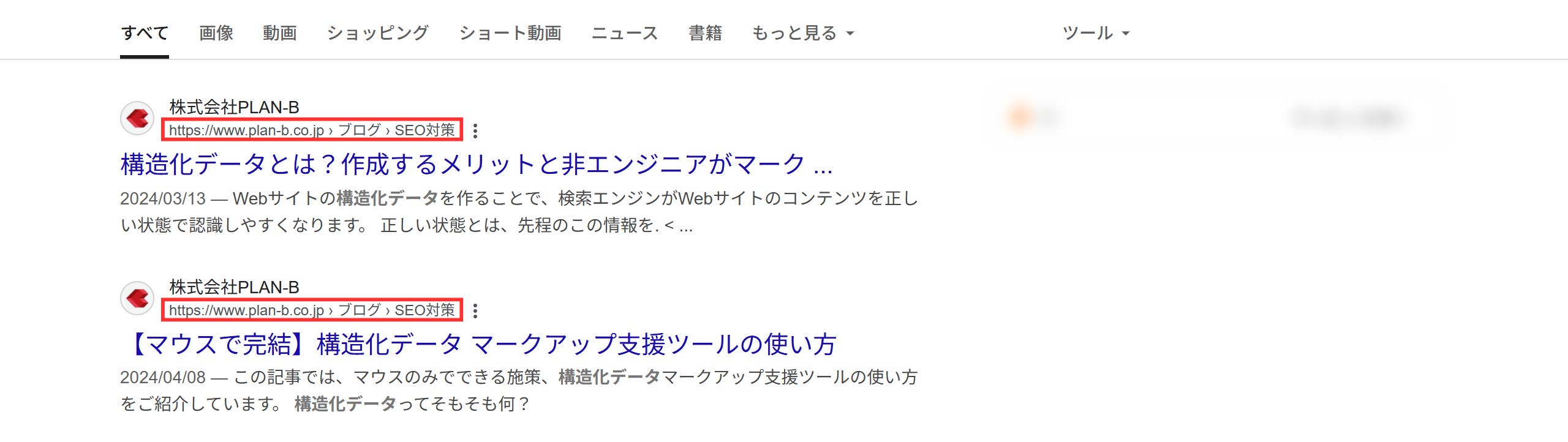
表示される情報は以下の通りです。
リッチリザルトに表示される情報
リッチリザルトは、構造化データによってクローラーに伝えられた情報がもとになっています。Webページに情報が記載されていても構造化データが実装されていなければ、検索エンジンがうまく理解できず、リッチリザルトに反映されない可能性があります。
そのためリッチリザルトで情報を表示するには、構造化データのマークアップを行うことが必要です。
リッチリザルトが表示されることで、クリック率の向上が期待できます。また、検索結果で既に有益な情報が得られるため、ユーザーからの信頼感や満足度も向上します。
構造化データをマークアップするときは、検索エンジンにも理解できるschema.orgという言語を使います。
マークアップの方法を紹介する前に、まずはschema.orgにおいてよく使われる要素を紹介します。
| 要素 | 概要 | リッチリザルトで表示される情報 |
| Article | ニュース記事やブログ記事などの文章コンテンツを示す | タイトル・著者・日付・画像など |
|---|---|---|
| BlogPosting | ブログに掲載された記事を示す(Articleの下位カテゴリ) | タイトル・著者・日付・画像など |
| NewsArticle | 報道機関によるニュース記事 | ニュースのタイトルやサムネイル |
| Product | 商品やサービスの情報を示す | 価格・在庫状況・レビュー・画像など |
| Review | 商品や記事などに対するレビューや評価を示す | 星評価やレビュー内容 |
| FAQPage | よくある質問(FAQ)とその回答を構造化して示す | FAQ |
| HowTo | 何かの手順・方法をステップごとに説明する内容を示す | 手順ごとの展開表示・画像つき手順など |
| Recipe | 料理のレシピや手順、材料、調理時間などを示す | 材料・調理時間・評価・画像など |
| Event | 開催されるイベントの情報を示す | 日時・場所・チケット情報など |
| Organization | 企業や団体の情報を示す | ロゴ・社名・公式SNSなど |
| Person | 個人の情報を示す | 名前・肩書き・画像など |
| WebSite | Webサイト全体に関する基本情報を示す | サイト名・検索ボックスなど |
| WebPage | Webページの内容やテーマを示す | Webページのタイトルや説明など |
| BreadcrumbList | サイト構造における階層関係を示す | パンくずリスト |
| VideoObject | 動画コンテンツの情報を示す | 動画のサムネイル・再生時間など |
構造化データをマークアップする際はschema.orgという言語を使い、JSON-LDという形式でHTMLに記述します。
JSON-LDとはGoogleが推奨している、構造化データをHTMLに記述する方法です。他にもMicrodataやRDFaがありますが、基本的にはJSON-LDの記述方法さえ知っておけば問題ありません。
先ほど例に挙げた以下の内容を、schema.orgを使ってJSON-LDの形式で記述します。
schema.orgを使ってJSON-LDの形式で記述した例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "WebSite", "name": "PINTO!", "url": "https://www.plan-b.co.jp/blog/", "publisher": { "@type": "Organization", "name": "PLAN-B" }, "description": "PINTO!は株式会社PLAN-Bが運営する、SEOやWebマーケティングに関する情報を発信するメディアです。" } </script> |
まず「<script type=”application/ld+json”>」 で、クローラーに対して「この中にはJSON-LD形式の構造化データが書かれています」と伝えます。
次の「@context”: “https://schema.org”」では、この構造化データが schema.org のルールに従って書かれていることを示します。
「”@type”: “WebSite”」は、Webサイト全体の情報に関するものであることを指定する記述です。
「”name”: “PINTO!”」では、Webサイトの名前である「PINTO!」を表します。
「”url”: “https://www.plan-b.co.jp/blog/”」で、クローラーに「このサイトの正確なアドレスはこれです」と知らせます。
「”publisher”: { “@type”: “Organization”, “name”: “PLAN-B” }」で表しているのは、Webサイトの運営者情報です。「@type」で「Organization」を用いて、法人によって運営されていることを、「name」で運営元が「PLAN-B」であることを明記します。
「”description”: “PINTO!は株式会社PLAN-Bが運営する、SEOやWebマーケティングに関する情報を発信するメディアです。”`」では、サイトの概要を示します。
💡WordPressのプラグインや構造化データマークアップ支援ツールでもマークアップできる
WordPressのプラグインや構造化データマークアップ支援ツールからも、構造化データをマークアップすることができます。
WordPressのプラグインを使えば、HTMLを直接触らなくても構造化データを生成することが可能です。また、自動でマークアップすることもできます。
一般的なサイトにはYoast SEO、レストランやECサイトなどリッチリザルトを積極的に狙いたい場合にはRank Math SEOがおすすめです。
また、Googleの構造化データマークアップ支援ツールでも実装することができます。
WordPressのプラグインや構造化データマークアップ支援ツールは、ご自身の用途や環境に合わせて最適なものを使ってみてください。
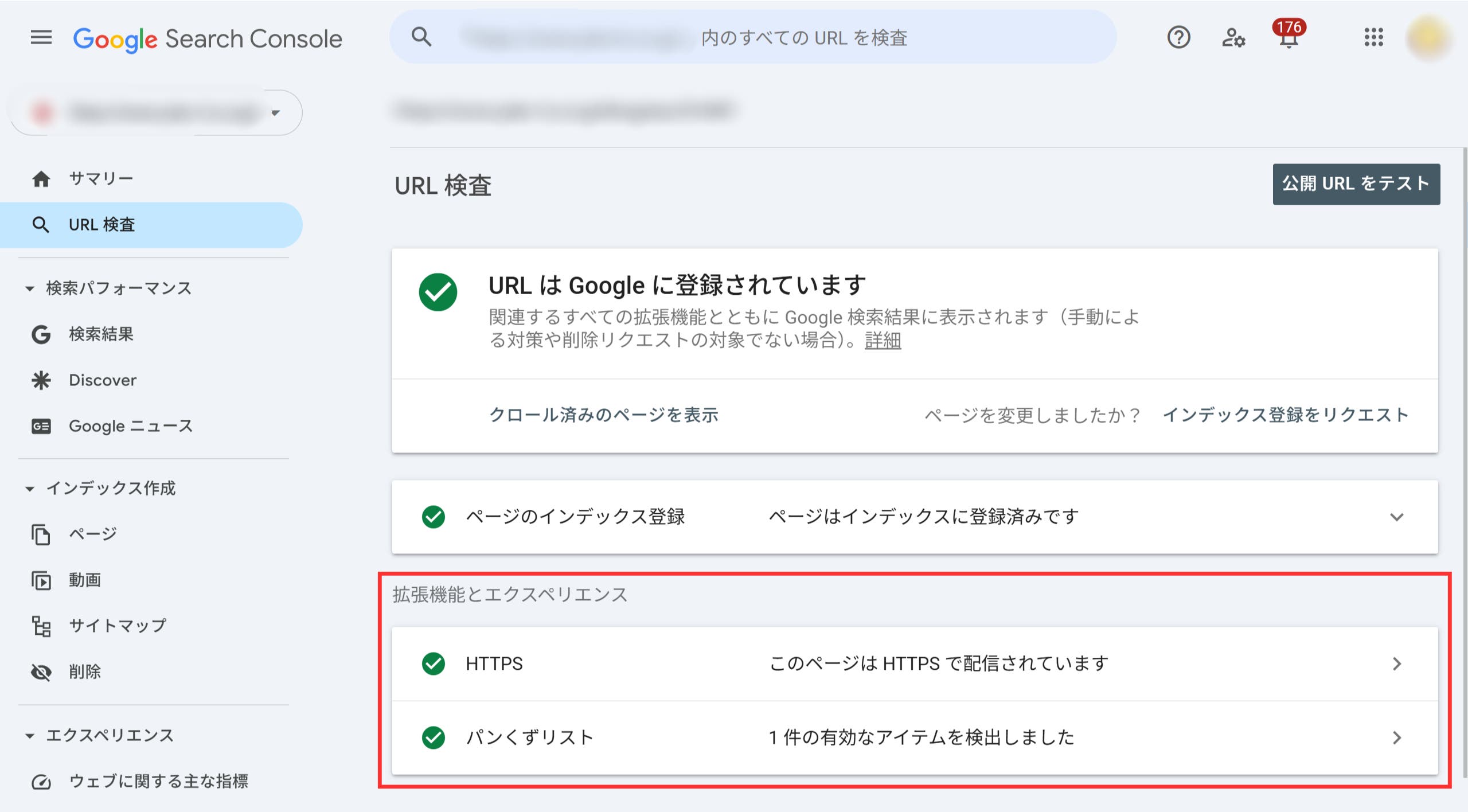
構造化データをマークアップした後は、Google Search ConsoleのURL検査ツールやリッチリザルトテストを使って、正しく実装されているかを確認しましょう。
URL検査ツールは、Google Search Consoleの上部の検索窓にURLを入れると使うことができます。
以下のような画面が表示されたら問題ない状態ですが、問題がある場合は赤枠内にエラーが表示されます。
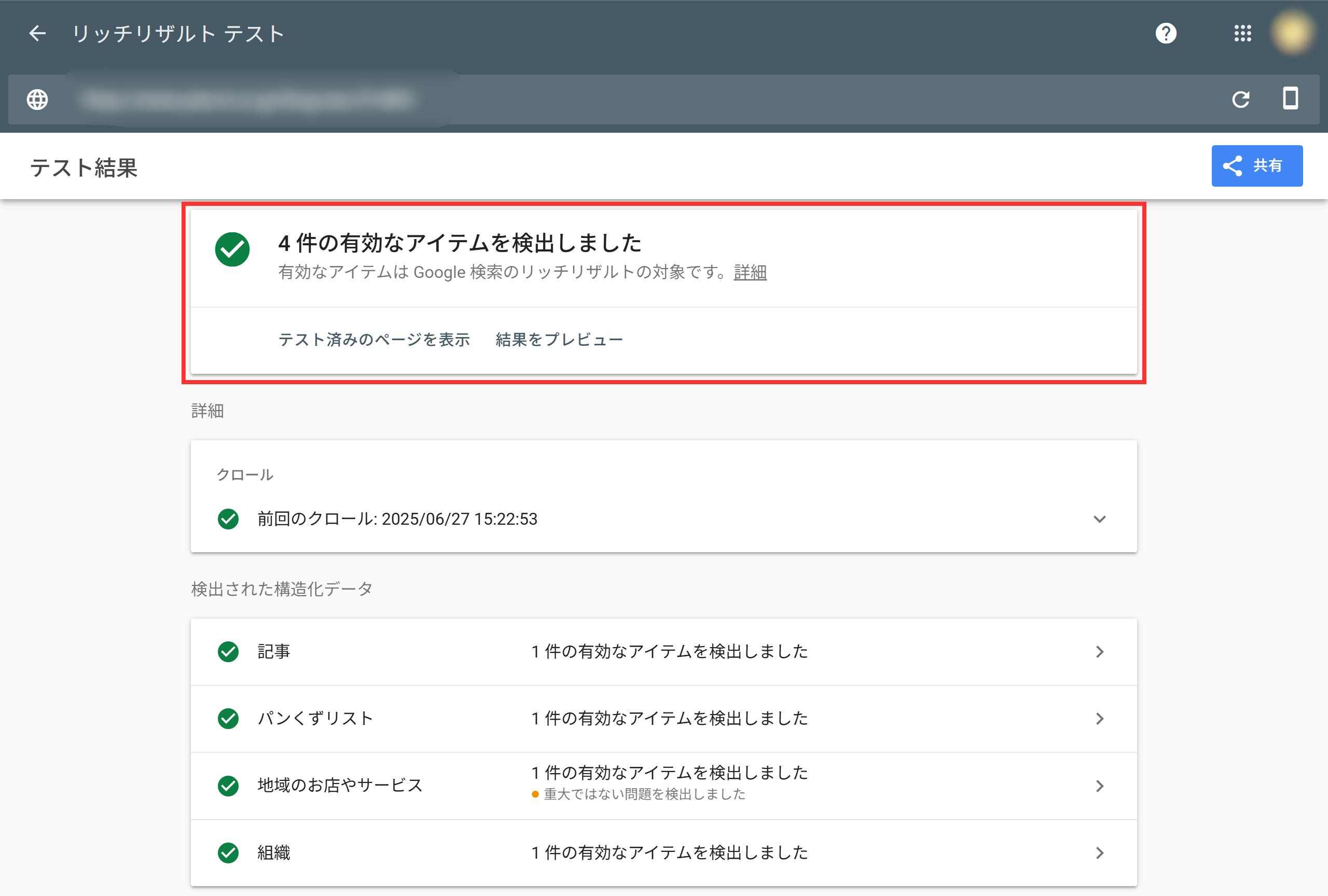
リッチリザルトテストでは該当ページのURLや構造化データのコードを入力することで、「このページがリッチリザルトに対応しているか = 構造化データを正しく認識しているか」を確認することが可能です。エラーのある場合は、以下画面の赤枠内に警告が表示されます。
構造化データをマークアップした後は、定期的に確認し更新することが重要です。
Googleは検索セントラルというポータルサイトで、技術仕様や効果的な施策を発信しており、構造化データに関する情報も、この検索セントラル上で更新されることがあります。最近では、AIモードに対応するためには構造化データを正しく実装する必要があると発表されました。
構造化データに関する情報の更新頻度はそれほど高くありませんが、更新情報を随時確認し、最新の仕様に沿って対応するのが望ましいです。
構造化データをマークアップする際には、Googleのガイドラインを遵守しましょう。
ガイドラインを守らなかった場合、検索エンジンはそのデータを無効として扱います。ガイドライン違反を繰り返した場合には、構造化データが検索結果に反映されなくなるだけでなく、手動ペナルティによって検索順位が下がる場合もあります。
構造化データ実装時に特に注意すべきGoogleのガイドライン
| 概要 | NG例 | |
|---|---|---|
| ページの内容とマークアップを一致させる | 構造化データに記述する情報は、実際にWebページ上に表示されている内容と一致させる | ページには商品情報のみが書かれているのに、構造化データにはレビューを記載していると書かれている |
| ガイドラインで定義された正しい形式を使用する | 要素を正しく使い、正しい形式で入力する | FAQページに構造化データを実装する際、FAQPageではなくWebPageやArticleなど不適切な要素を記述する |
| 構造化データのスパム的な使用をしない | 検索順位やクリック率を高めるために、存在しない情報をマークアップしたり、同じ内容を過剰に重複記述したりしない | ユーザーのレビューが1件も投稿されていないにもかかわらず、構造化データに「星5つ」「レビュー数:100件」といった虚偽の評価情報を入力する |
Googleは、構造化データの対応方法やガイドラインを適宜アップデートしています。定期的に確認し、必要があれば修正することが重要です。
構造化データをマークアップする際は、schema.orgの要素をむやみに併用しないようにしましょう。
構造化データは、ページの内容を検索エンジンに正確に伝えるためのものであり、ページの内容に合わない複数の要素を併用すると、検索エンジンが内容を誤解してしまう可能性があります。
例えば記事を構造化データでマークアップする場合、Articleの他にFAQPageやProductなどの無関係な要素を加えると、どれが主なコンテンツなのか判断できない状態になります。これにより、リッチリザルトが正しく表示されなかったり、ガイドライン違反として取り扱われたりする可能性が高いです。
ページの主な内容に一致したスキーマタイプを一つ選んだ上で、レビューや動画などの関連情報がある場合は、その中に入れ子で記述することを、Googleでは推奨しています。
💡関連情報がある場合の記述方法
関連情報がある場合は、ページの主な内容に一致したスキーマタイプを一つ選んだ上で、関連情報を入れ子で記述すると説明しました。では、具体的にどうやって記述すればよいのでしょうか?
以下の情報を構造化データにする場合を例に挙げます。
この場合、構造化データでは以下のように記述します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "@context": "https://schema.org", "@type": "Article", "headline": "おすすめコーヒーメーカーのレビュー", "author": { "@type": "Person", "name": "田中一郎" }, "review": { "@type": "Review", "reviewRating": { "@type": "Rating", "ratingValue": "4", "bestRating": "5" }, "author": { "@type": "Person", "name": "山田花子" } } } |
通常の場合と同じように、まずは「”@context”: “https://schema.org”」から「”name”: “田中一郎”」の部分で、メインの内容について記述します。
次の「”review”」から「”name”: “読者A”」までが、関連情報について説明している部分です。
「review」は、この記事に読者によるレビュー情報が含まれていることを示し、「”@type”: “Review”」で、その情報がレビューであることを明確に定義します。
そして「”reviewRating”: { “@type”: “Rating”」では、「このレビューには数値による評価情報が含まれており、それはRating(評価)というタイプのデータです」と示しています。「”ratingValue”: “4”」と「”bestRating”: “5”」は、読者が5点満点中4点の評価を付けたという意味です。
「”author”: { “@type”: “Person”, “name”: “山田花子” }」により、このレビューを投稿したのが山田花子という名前の個人であることが示されています。
構造化データは、Webサイトの情報をクローラーに正しく伝えるための重要な要素で、リッチリザルトの表示や検索エンジンによるコンテンツの正確な理解に役立ちます。
「自社だけで実施するのはハードルが高いかも」と思われた方は、ぜひSEOコンサルティングサービスへご相談ください。
■株式会社PLAN-Bについて
SEO対策やインターネット広告運用などデジタルマーケティング全般を支援しています。マーケティングパートナーとして、お客様の課題や目標に合わせた最適な施策をご提案し、「ビジネスの拡大」に貢献します。
■SEOサービスについて
①SEOコンサルティング
SEO事業歴19年以上、SEOコンサルティングサービス継続率95.3%※の実績に基づき、単なるSEO会社ではなく、SEOに強いマーケティングカンパニーとして、お客様の事業貢献に向き合います。
②SEOツール「SEARCH WRITE」
「SEARCH WRITE」は、知識を問わず使いやすいSEOツールです。SEOで必要な分析から施策実行・成果振り返りまでが簡単に行える設計になっています。
■その他
関連するサービスとしてWebサイト制作や記事制作、CROコンサルティング(CV改善サービス)なども承っております。また、当メディア「PINTO!」では、SEO最新情報やSEO専門家コラムも発信中。ぜひ、SEO情報の収集にお役立てください。
※弊社「SEOコンサルティングサービス」を1ヶ月を超える契約期間でご契約のお客様が対象
※集計期間(2024/01~2024/12)中に月額最大金額を20万円以上でご契約のお客様(当社お客様の87%は月額最大金額が20万円以上)が対象

専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。
share

SEO対策
最終更新日:2026.05.07

SEO対策
最終更新日:2025.07.29

SEO対策
最終更新日:2023.10.30

SEO対策
最終更新日:2026.04.17

SEO対策
最終更新日:2026.04.21

SEO対策
最終更新日:2023.09.15

SEO対策
最終更新日:2024.04.24

SEO対策
最終更新日:2025.07.29