
【2026年版】SEOとは?初心者向けに具体例や事例を紹介
SEO対策
最終更新日:2026.03.02
![]()
更新日:2022.12.23

Googleは2019年10月25日、最新の自然言語処理技術”BERT”を検索エンジンに採用したと発表しました。発表当初は英語圏のみでしたが、続けて同年12月10日には日本語圏を含む70以上の言語においても導入されたことがGoogleより発表されたのです。
この自然言語処理技術”BERT”は「過去最大のアップデート」などと日本メディアでも大きく取り上げられており、SEOにおいてどれほど影響があるのか知りたいと考えている人も多いでしょう。
この記事では、BERTとはそもそもどういう技術でどのような特徴があるのか、導入の背景や今後のSEO対策を踏まえてご紹介します。
SEOに関しての基本的な知識をつけたいという方はこちらのSEO完全攻略キットもご活用ください!

※フォーム送信後、メールにて資料をお送りいたします。
専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
※フォーム送信後、メールにて資料をお送りいたします。

フォームでの問い合わせが
完了いたしました。
メールにて資料をお送りいたします。
今回Googleが検索エンジンに導入した最新自然言語処理技術である”BERT”。
まずはそもそも自然言語処理技術とは何か、なかでもBERTとはどういう特徴があるのかについて説明します。
今回、Googleが検索エンジンに採用したBERTとは一体どのようなものなのでしょうか。
BERTとは、自然言語処理技術(以下NLP: Natural Language Processing)の一種です。
“Bidirectional Encoder Representations from Transformers”の頭文字をとったもので、読み方は「バート」と読みます。
NLPとは、私たち人間が使う言語をコンピュータに理解させるための技術を指します。
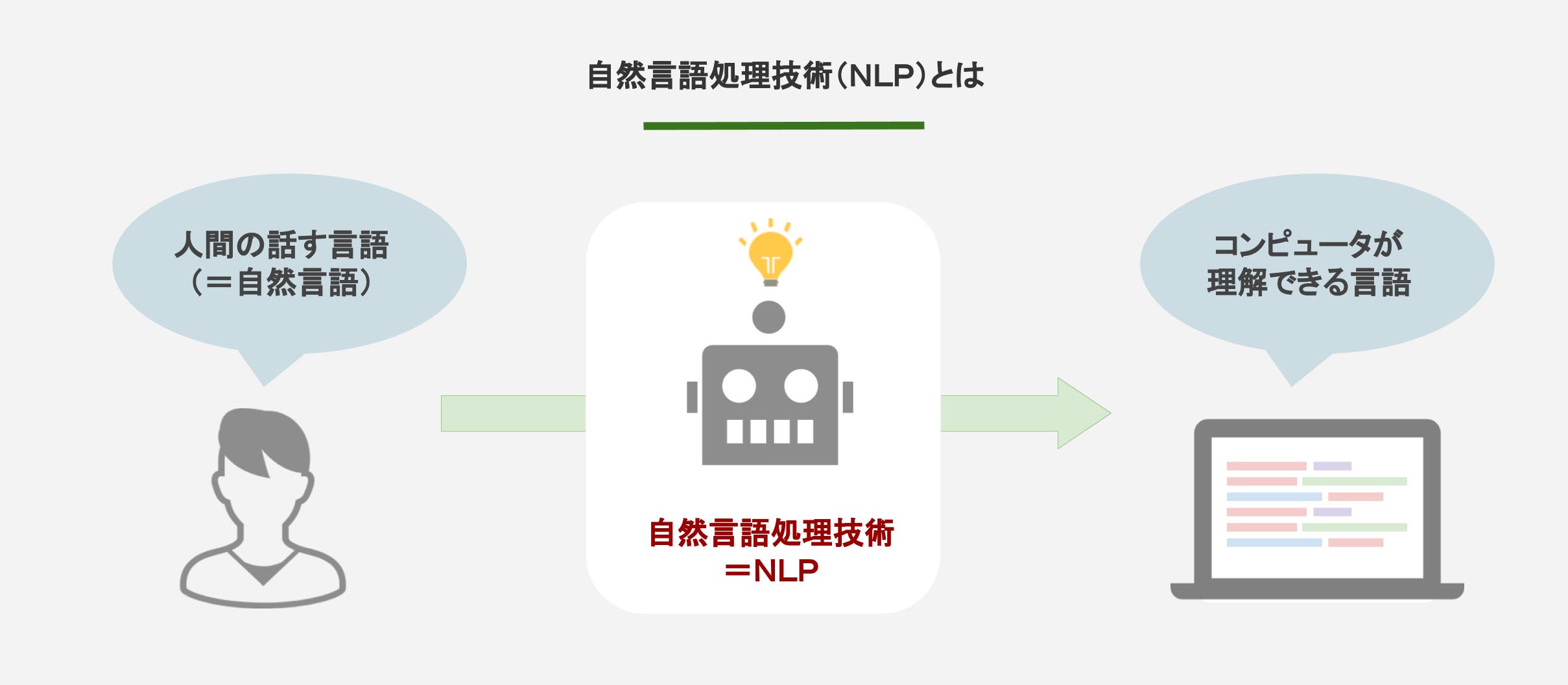
Google検索で、検索エンジンが私たちの検索意図に合わせて適切なサイトを表示するために、このNLPが人間の検索ワードをコンピュータに理解させてくれているのです。
最新のNLPであるBERTが検索エンジンに採用されたということは、私たちの検索ワードをより深く理解するためのGoogleの試みであるともいえるでしょう。
BERTとは他のNLPと違って何がすごいのでしょうか。ここではデータ処理の仕組みや学習工程については触れず、検索エンジンとして機能する特徴をご紹介します。
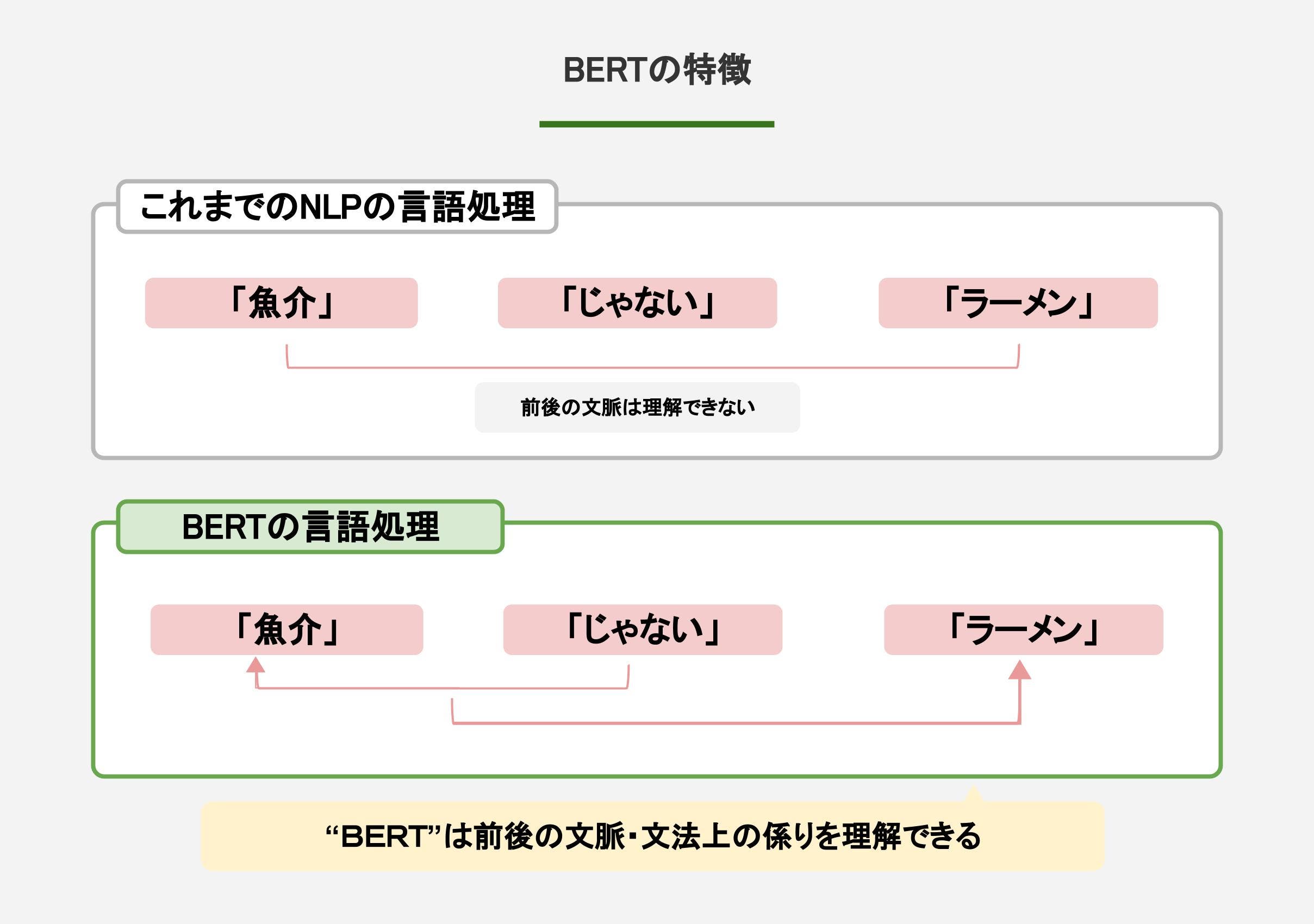
なんといってもBERT最大の特徴とは、文章における「文脈を理解できること」です。
これまでのNLPでは私たち人間が話す文章のうち、それぞれの単語については理解できるものの、その単語同士のつながり、つまりは文脈を読み取ることはできませんでした。
そのため検索ワードによってはうまく検索意図を汲み取ってもらえず、ユーザーが求めている検索結果へとつながらないこともあったのです。
それがこのBERTアップデートにより、会話型のクエリやより複雑な条件を含んだ検索クエリに対しても、正確に検索結果を返せるようになったのです。
では具体的に、「魚介じゃないラーメン」というワードを例にしながら、その特徴をご説明したいと思います。
たとえば、現在BERTが導入されていない日本語のGoogle検索で「魚介じゃないラーメン」と検索すると、検索結果画面には「魚介ラーメン」の店舗ばかりが表示されます。
つまり、BERTアップデート以前のNLPは「魚介じゃないラーメン」と「魚介 ラーメン」がほぼ同様に認識されていたということになります。
なぜこのようなことが起きるのでしょうか。
これまでのNLPでも「魚介じゃないラーメン」というワードを、「魚介」「じゃない」「ラーメン」という3つの要素に分解し、個々を個別に理解することは可能でした。
しかし、英語の”not”にあたる「じゃない」という単語が、文法上「魚介」にかかっているということを認識できていませんでした。
そのため文章の中でも意味がはっきりとしている「魚介」「ラーメン」という2語のみが強調されてしまい、「じゃない」が無視される形で検索結果が表示される形となっていたのです。
では、BERTでは「魚介じゃないラーメン」をどのように認識しているのでしょうか。
BERTはNLPの中でも、文章の文脈、つまりは文法を理解することができるのがその特徴です。
つまり、「魚介じゃないラーメン」のうち、「じゃない」という単語が「魚介」にかかるという文法上の構造を理解することができるのです。
このようなBERTの処理能力の高さは、今回例にした「魚介じゃないラーメン」のような短いワード以上に、「銀座駅で10分以内に魚介じゃないラーメンを食べたい」などの文章となった場合に、より力を発揮します。
現時点ではまだうまく反映はされていないクエリもありますが、「小麦じゃないパスタ」などと検索すると、「グルテンフリーのパスタ」や「小麦不使用のパスタ」、「玄米のパスタ」などが結果として表示されるようになっています。
「魚介じゃないラーメン」も将来的には、「魚介 ラーメン」とはまったく異なる結果を表示してくれるようにもなることでしょう。
ここまでで、BERTが他のNLPとどう違うのか、その特徴をわかっていただけたかと思います。
では、この最新技術BERTがなぜ今検索エンジンに用いられることとなったのでしょうか。またBERTにより検索結果画面はどう変化するのでしょうか?
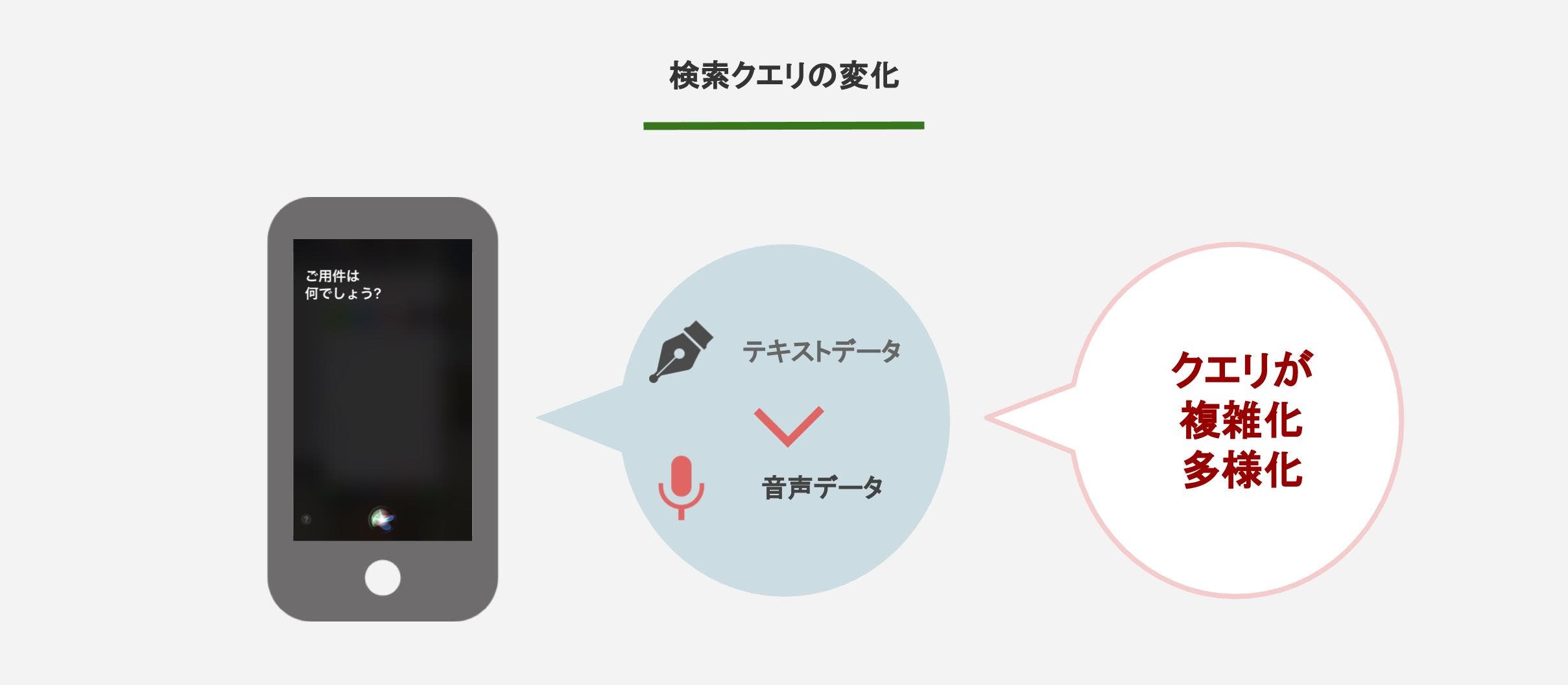
導入背景には大きく2つの理由が挙げられます。まず一つはモバイル端末の普及による検索クエリの多様化です。
近年、モバイル端末の普及によって、ユーザーの検索するデバイスもPCやデスクトップから、スマホが主流になりつつあります。この移行に伴って、「検索する」という行為は間違いなく私たちにとってより日常的になりました。
このように検索ワードが多様化したことで、検索エンジンにもより高い処理能力が求められるようになったことが背景にあります。今でも日々Google検索で検索されるワードの15%は全く新しいワードだそうです。
またAndroidを搭載するスマートフォンの「OK Google」、Apple社製品の「Shiri」、そのほかにもEco端末の「Alexa」など、音声検索システムやスマートスピーカーの普及も高まりつつあります。
これにより単語による検索だけでなく、音声による検索の機会もぐっと増えてきました。
ComScore社の調査によると、「すべての検索の50%が2020年までに音声検索になる」※1と言われているだけでなく、「検索の約30%は2020年までに画面なしで行われます」※2と予測した調査データも存在します。
こうした音声検索では、話し言葉に近い口語的な形で検索されます。口語的な検索では、文章や単語による検索とは、文脈の意味やニュアンスが大きく異なってきます。
この音声検索や文章での検索が増加したことで検索ワードが複雑化したことが、もう一つの導入背景だと考えられます。
音声検索について詳しく知りたい方は次の記事を参考にしてみてください。
| 検索は“声の時代”へ|音声検索に対応するコンテンツとは |
このように、検索という行為の日常化や音声検索の増加によって、検索ワードが多様化・複雑化したことが、今回のBERTの導入背景として挙げられます。
| ※1 campaign:Just say it: The future of search is voice and personal digital assistants ※2 MediaPost:Gartner Predicts 30% Of Searches Without A Screen In 4 Years |
BERTが具体的にどのような条件でテストを行った際に好成績を出すことが出来たのか、GLUEベンチマーク(General Language Understanding Evaluation)という例を簡単に紹介します。
GLUEベンチマーク(General Language Understanding Evaluation)[Wang, A.(2019)]とは8つの自然言語理解タスクに対してテストをし、評価するものです。
8つの自然言語理解タスクは以下ですが、いずれのテストでもSoTAモデルであるOpenAI GPTといった既存モデルよりも良い結果をもたらしました。
| データセット | タイプ | 概要 |
| MNLI | 推論 | 前提文と仮説文が含意/矛盾/中立のいずれか判定 |
| QQP | 類似 | 2つの疑問文が意味的に同じか否かを判別 |
| QNLI | 推論 | 文と質問のペアが渡され、文に答えが含まれるか否かを判定 |
| SST-2 | 1文分類 | 文のポジ/ネガの感情分析 |
| CoLA | 1文分類 | 文が文法的に正しいか否かを判別 |
| STS-B | 類似判定 | 2文が意味的にどれだけ類似しているかをスコア1~5で判別 |
| MRPC | 類似判定 | 2文が意味的に同じか否かを判別 |
| RTE | 類似判定 | 2文が含意しているか否かを判定 |
では、多様化・複雑化したクエリを理解するためにBERTを導入すると、Google検索はどのように変化するのでしょうか。
実際にGoogleはBERT導入前後の変化について、いくつか例を挙げています。
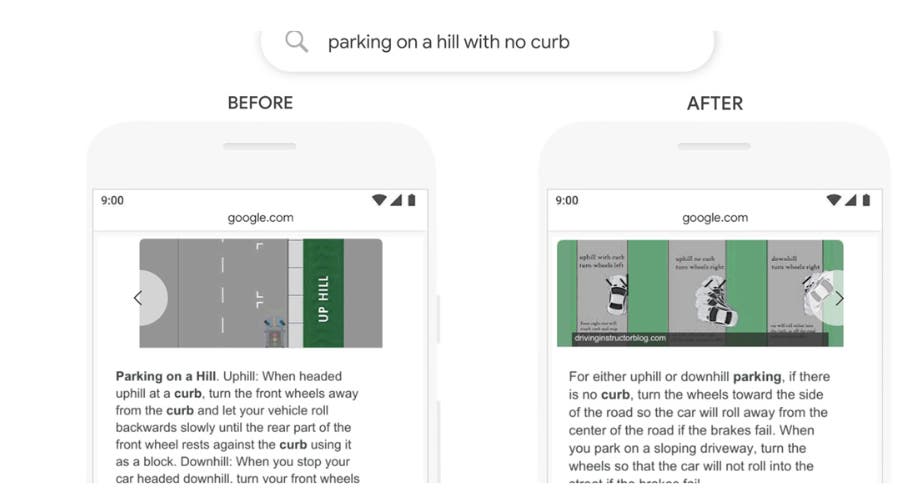
■検索ワード:”parking on a hill with no curb”(縁石のない坂道に駐車)
■BERT導入前:それぞれの単語を個別に理解する従来のNLPでは、”curb” (縁石)の直前の”no”がどの単語にかかるのかを理解できないため、「縁石のあり/なし」に関係なく、「上り坂と下り坂の駐車方法の違い」を説明するページを上位表示させる。
■BERT導入後:まず”no”を”curb” (縁石)にかかる語として認識し、”no curb”(縁石のない)の意味を汲み取れます。その結果、「縁石のあり/なし」における駐車方法の違いを説明したページを上位表示させる。
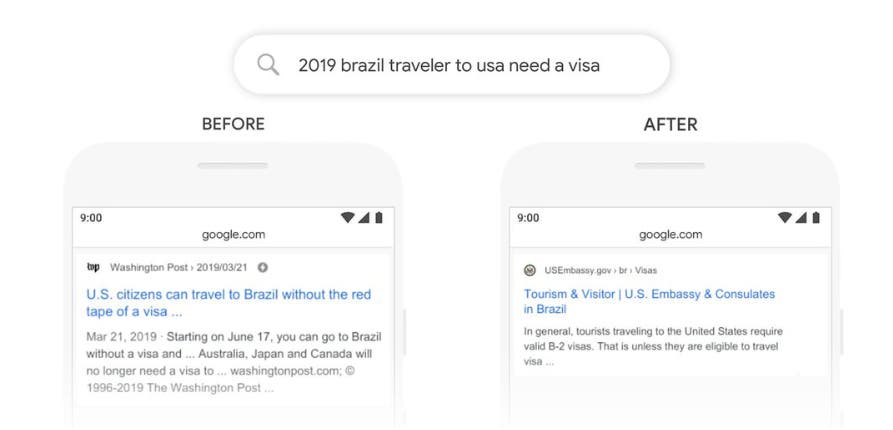
■検索ワード:”2019 brazil traveler to usa need a visa”(2019年、アメリカに行くブラジル旅行者はビザが必要)
■BERT導入前:目的を示す”to”の文法上の意味や前後のつながりを理解できないため、旅行する主体をアメリカ人にしてしまう。その結果、アメリカ人がブラジルを旅行する際のビザに関する情報ページを上位表示させる。
■BERT導入後:文中の”to”と前後の関係を理解し、質問通りブラジル人を旅行の主体として認識できる。その結果、アメリカ大使館がブラジル人旅行者向けに提供しているビザ情報ページを上位表示させる。
このように、すでにBERTが導入されている英語圏のGoogle検索では、「魚介じゃないラーメン」で示したように、文章の文脈理解を反映させた検索結果が表示されています。
現在、英語圏でのGoogle検索で、上記のような改善事例は検索結果全体の10%に見られたそうです。
BERTの言語処理技術は強調スニペットにも影響します。
また強調スニペットにおいては、現在提供されている20数か国の全ての国で、すでにBERTが適用されており、韓国語、ヒンディー語、ポルトガル語の3語で大きな改善が見られたそうです。
これについて大きな改善があったというニュースはありませんが、強調スニペットでは、日本でもすでに影響しています。
さらに、BERTによる影響は、検索ボリュームが多いビッグワード以上に、複雑な文脈理解が必要となるテールワードに見られると推測されます。
さらに、これまでのNLPとの相違は、テールワード以上に音声検索などの、文章や会話調になったクエリで大きく表れてくるのは間違いないでしょう。
最後に、BERTの導入に備えて、SEO業者や社内のSEO担当者が行うべき対策について触れたいと思います。
結論をいうと、”BERT”導入に向けた特別な対策は不要です。
そもそもBERT導入は、複雑化・多様化する検索クエリに対応できるよう、GoogleがこれまでのNLP以上に各クエリの”意味”や”検索意図”を正確に読み取れる仕組みを導入したということです。
つまり、「ユーザーの検索意図を満たすような、ニーズに応じた良質なコンテンツを作る」という本質は変わっていないのです。
ただし検索クエリの精度が高くなっているため、これまで以上にコンテンツのわかりやすさや伝わりやすさが求められるようになってくることは確かでしょう。
また検索クエリとコンテンツの中身に大きな違いが起こらないよう、検索意図にあわせたコンテンツ制作を意識することが重要となります。
また読みやすいようレイアウトや見出しを整えたり、文章自体も複雑になりすぎないよう読みやすくする工夫や配慮も大切です。
漢字とひらがなをバランスよく使い、長すぎる文は適切な長さにするなどし、読み手の理解が高まるだけでなくGoogleにも認識されやすくもなります。
特殊な施策や対策は不要ですが、BERTの特性を理解し検索クエリに対する答えがコンテンツ内にしっかりと反映されているかといった確認は必要となるでしょう。
Googleは人間の自然言語における、前後の文脈を読み取れるNLP、BERTを検索エンジンに導入しました。
まだ大きな影響は見られないものの、日本でも強調スニペットの生成には、すでにBERTが関係しています。
BERT導入によってGoogle検索の検索エンジンは、これまで以上にユーザーの検索意図を汲み取ることができるため、SEO対策としては、よりユーザーニーズに即した良質なコンテンツを作ることが重要となります。
強いて言うならば、よりユーザーの検索意図を汲み取った良質なコンテンツを作ることが、SEO対策に求められていると言えるでしょう。

専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。
share

SEO対策
最終更新日:2026.03.02

SEO対策
最終更新日:2025.07.29

SEO対策
最終更新日:2023.10.30

SEO対策
最終更新日:2025.06.09

SEO対策
最終更新日:2025.09.03

SEO対策
最終更新日:2023.09.15

SEO対策
最終更新日:2024.04.24

SEO対策
最終更新日:2025.07.29