

【アフィリエイト初心者向け】おすすめASP20種を紹介
Web広告
最終更新日:2025.02.13
![]()
更新日:2023.04.17
Webサイトを運用するにあたり、収集したデータを分析し戦略的な意思決定をどの程度行えているでしょうか。WebサイトやSNSといったチャネルの多様化に伴い、商品やサービスを購入するまでのプロセスが複雑化し、マーケティングの意思決定のために大量のデータを取り扱う必要が出てきました。そのようなシーンでは「BigQuery(ビッグクエリ)」の活用がオススメです。
2023年6月のユニバーサルアナリティクス(以下、UA)のサポート終了に伴い、Googleアナリティクス4(以下、GA4)への移行を進めている企業は多いと思われます。UAではBigQueryとの連携機能は有償版のみとなっていましたが、GA4では無償版でもBigQueryに対応するようになりました(無償版GA4は100万イベント/日の上限あり)。BigQueryであれば大量のデータを数秒で集計することができるので、皆さんの日々のマーケティング業務を強力にサポートしてくれる存在となるはずです。
本稿では、そんなBigQueryの概要や具体的な使い方、料金などを紹介します。

※フォーム送信後、メールにて資料をお送りいたします。
弊社の会社概要と、ケイパビリティのご紹介資料です。ご覧いただき、お気軽にお問い合わせください。
※フォーム送信後、メールにて資料をお送りいたします。

フォームでの問い合わせが
完了いたしました。
メールにて資料をお送りいたします。
BigQueryの紹介の前に、「Google Cloud Platform」(以下、GCP) について触れておきましょう。
GCPはGoogleが提供するクラウドコンピューティングサービスの総称です。データ解析だけでなく仮想マシン・ネットワークの構築やウェブアプリケーションの実行、機械学習の実装といった、様々な用途に対応するツールが用意されています。Googleならではの安定性とスピード、セキュリティを実現していながら一定容量までは無料で利用可能のため、導入のハードルは比較的低いと言えます。BigQueryはそんなGCPの中の一機能として提供されている「データウェアハウス(DWH)」です。元々はGoogle社内で使われていたデータ分析基盤を、外部向けに公開したのがBigQueryの始まりと言われています。
次に、そもそもデータウェアハウスとは何かについて紹介します。
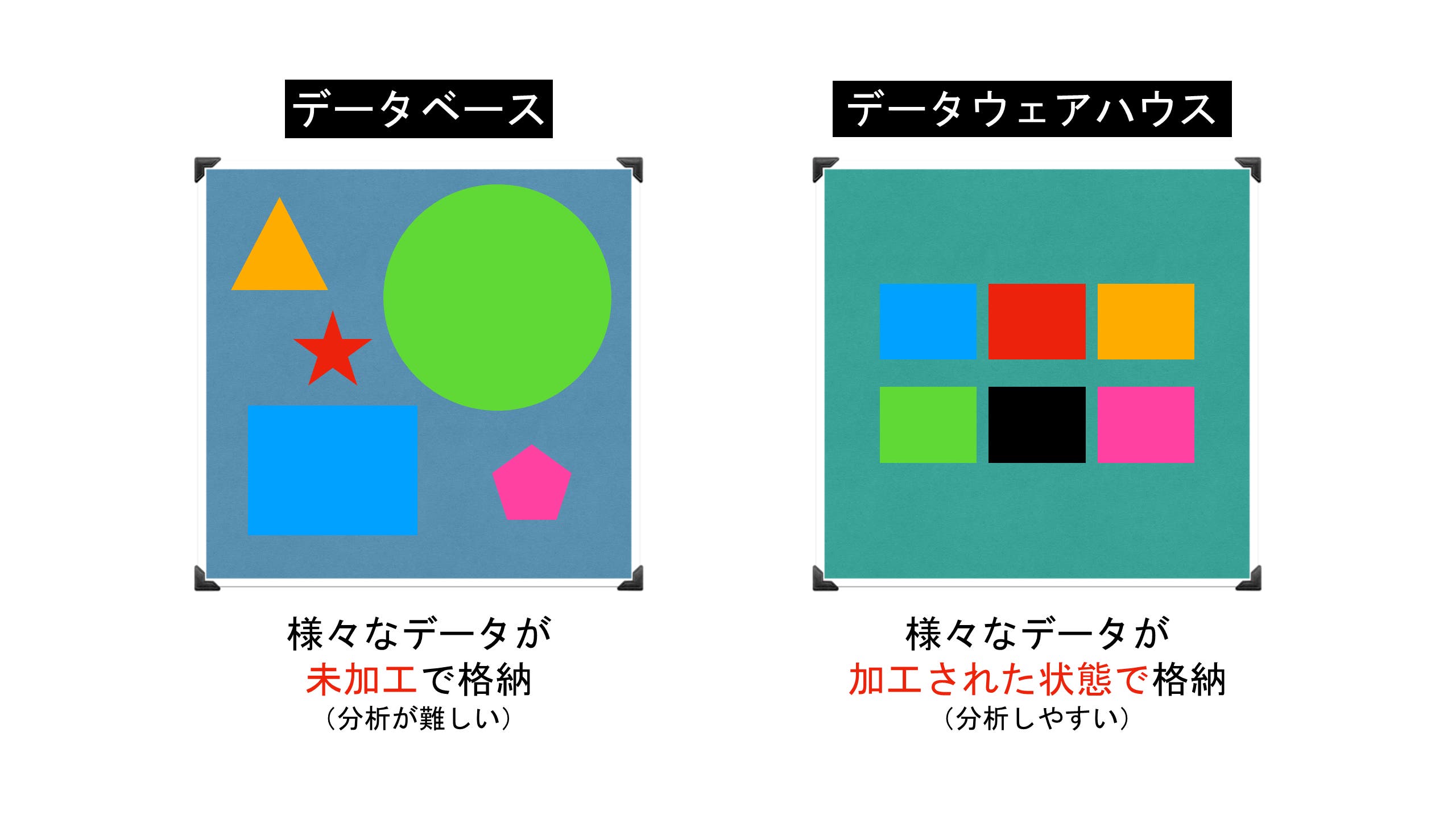
データウェアハウスとは、直訳すると「データの倉庫」という意味で、組織内の膨大なビジネスデータを加工して格納している場所を表します。データを格納した場所と聞くと、一般的には「データベース」という言葉を連想される方もいらっしゃると思いますが、この二つには明確な違いがあります。データベースには業務システムやWebサービスを運用する中で取得された「生のデータ(ローデータ、Raw Data)」が蓄積されています。データ量は膨大であり、未加工の状態なのでそのまま分析に用いるのは困難です。 一方でデータウェアハウスには、データベースのデータが分析しやすい形に加工された状態で格納されています。
例として大規模ECサイトを運用しており、各ユーザーの閲覧ログを取得しているケースを想定します(あくまでイメージのため簡易的な設計にしておりますが、実際の業務システムは多くの場合これよりもずっと複雑です) 。閲覧ログの「生のデータ」として、「ユーザーID」「閲覧日時」「閲覧URL」をリアルタイムで取得しているとします。ここから「今月はどのような商品が多く閲覧されているか」を分析したいとき、それぞれのデータがバラバラに格納されている生のデータのままでは分析は困難です。そこで、この閲覧ログデータを分析しやすい形に加工します。
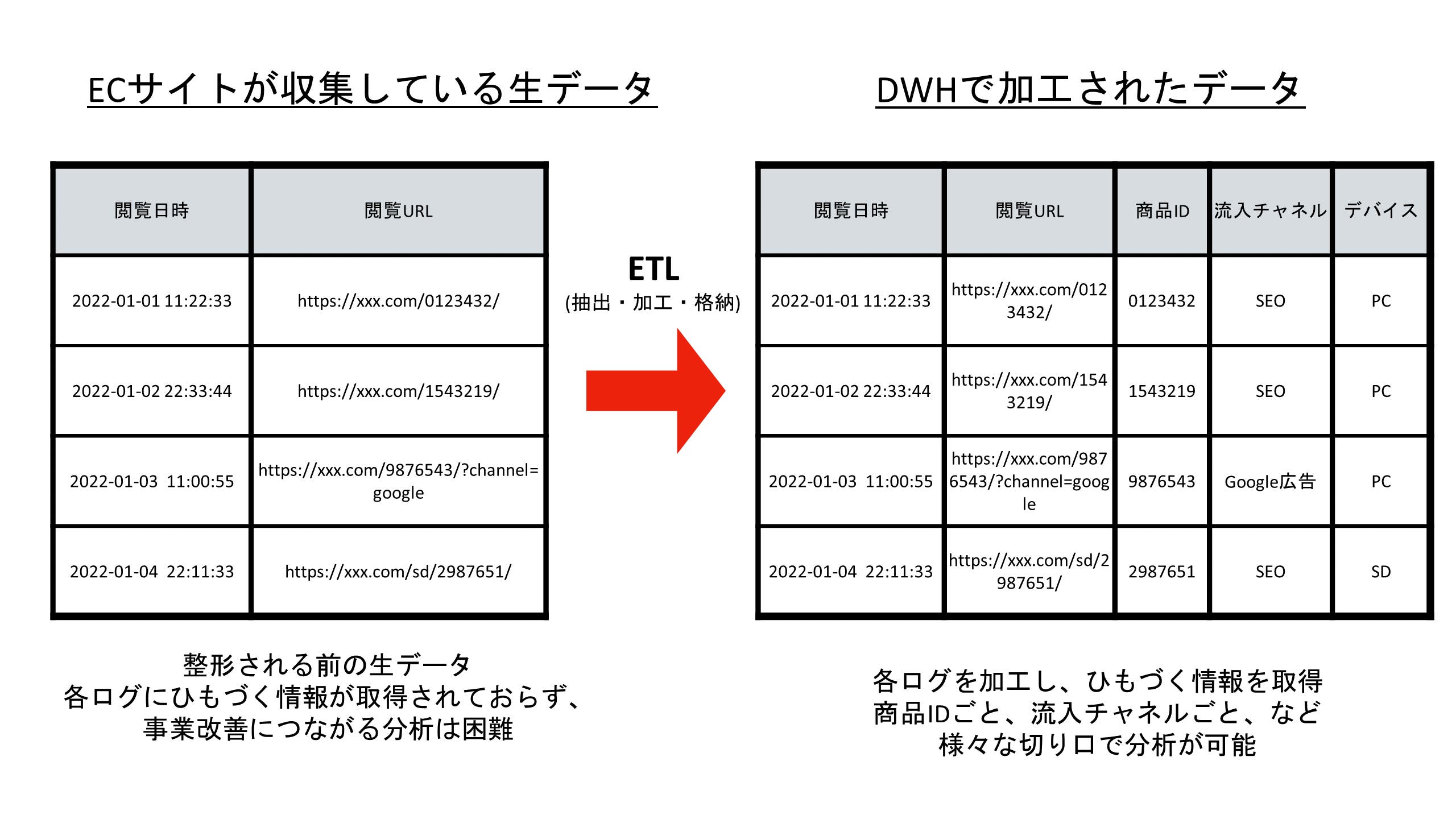
具体的には、閲覧URLを基に閲覧されていた商品を特定し、ユーザーIDや閲覧日時、閲覧商品IDの形式に変換します。こうすれば、商品IDごとに閲覧回数を集計することは容易ですし、今月多く閲覧された商品のランキングなどもすぐに作成できます。 余談ですが、このようにデータを抽出(Extract)し、分析しやすい形に加工(Transform)して格納(Load)する工程を、ETLと呼びます。
まとめると、データベースとデータウェアハウスは目的が異なり、前者は蓄積用、後者は分析用と言えます。また、データウェアハウスはデータベースのデータをETLして作成されています。
ここからはBigQueryの特徴や具体的に何ができるのかを3つ紹介していきます。
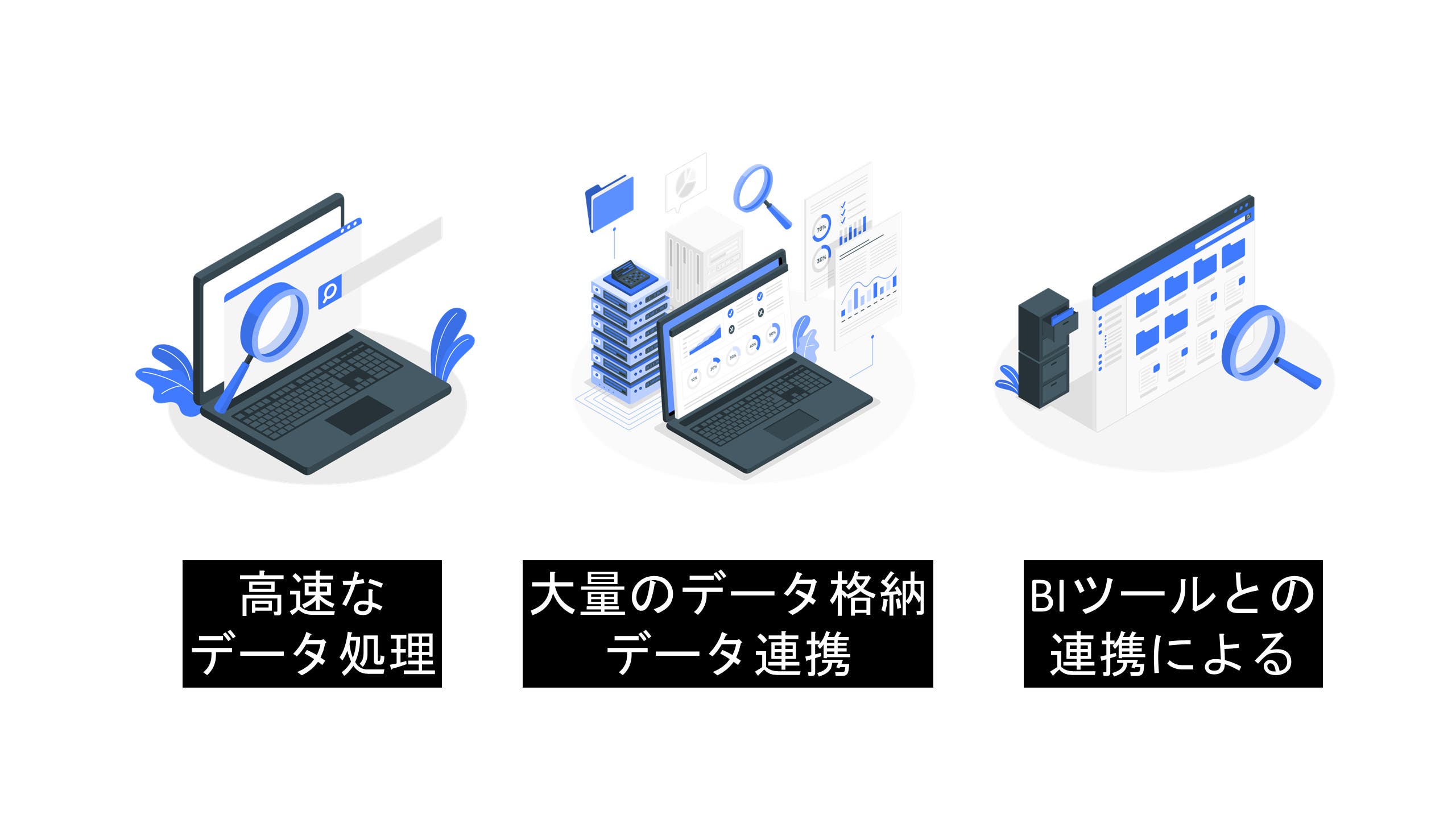
第一の特徴は何といっても、圧倒的なデータ処理速度にあります。BigQueryでは、数TB(テラバイト)、数PB(ペタバイト)のデータをも扱うことができ、数秒~数分で分析結果を出力できます。これほどの大容量のデータはExcelやスプレッドシートでは分析はおろか、データを開くことすらできずにアプリケーションが異常終了してしまいます。
第二の特徴は、各種ツールやデータソースと連携して大量にデータを格納できる点です。具体的にはGoogleサーチコンソールやGoogleアナリティクスとデータを連携したり、CSVファイルのデータを格納して処理できます。前者のデータ連携の詳細については本稿では割愛しますが、本稿の後半で手持ちのデータをBigQueryに格納して分析する例を紹介します。
第三の特徴は、Google社の提供するBIツール(※)である「Googleデータポータル」との連携が可能である点です。Googleデータポータルを用いることで、BigQueryによる分析結果を視覚的、直感的に分かりやすい形で図解できます。非エンジニアのチームメンバーに向けたレポーティング資料としても大いに力を発揮してくれます。
※BIツールとは、膨大なデータから必要な情報を抽出し可視化するツールです。
データポータルの使い方については、こちらの記事も参考にしてみてください。
次に、BigQuery利用時に発生する料金について紹介します。 料金は以下の3種類です。
・オンデマンド分析の料金
クエリを実行時、クエリでスキャンされたデータに対して発生する料金
・ストレージ料金
BigQueryにデータを保存する費用。アクティブストレージと長期保存の2つに分かれる
・データ取り込み料金
テーブルにデータを挿入するときに発生する料金
オペレーション | 料金 | 詳細 |
クエリ(オンデマンド) | 6 USD (1TBあたり) | 毎月1TBまで無料 |
アクティブストレージ | 0.02 USD (1GBあたり) | 毎月10GBまで無料 過去90日間で変更されたテーブル |
長期保存 | 0.01 USD | 毎月10GBまで無料 90日間連続して変更されていないテーブル |
データ取り込み | 0.01 USD (200MBあたり) | 挿入に成功した行が課金対象 |
参照元: https://cloud.google.com/bigquery/pricing?hl=ja
では、BigQueryを用いた具体的なデータ分析方法をご紹介していきます。まずは、BigQueryの初期セットアップを行いましょう。
STEP 01: 最初にBigQueryのコンソールを開きます。
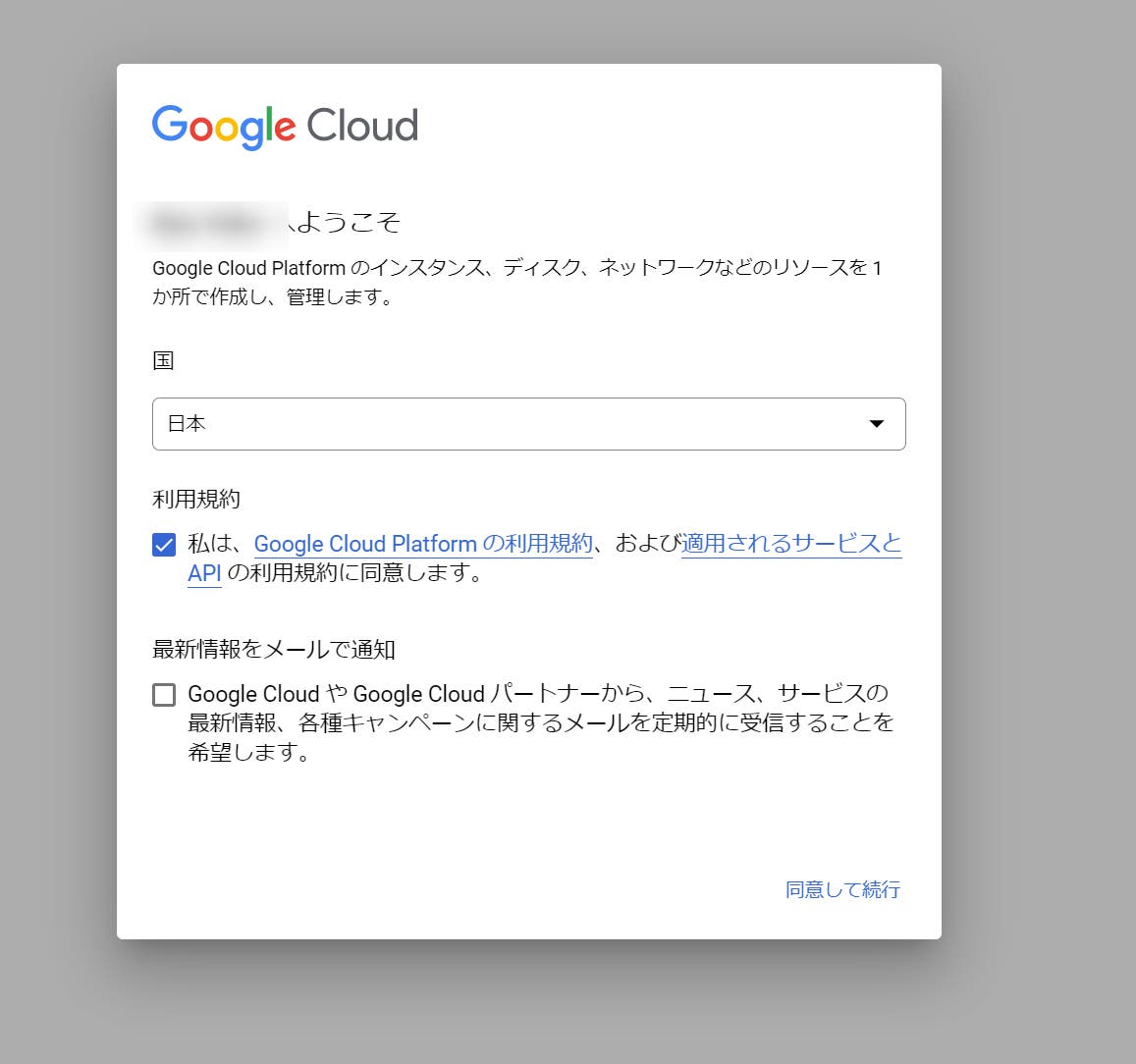
STEP 02:初めてGCPにアクセスしたときは上図のような画面が表示されますので、利用規約に同意して続行します。
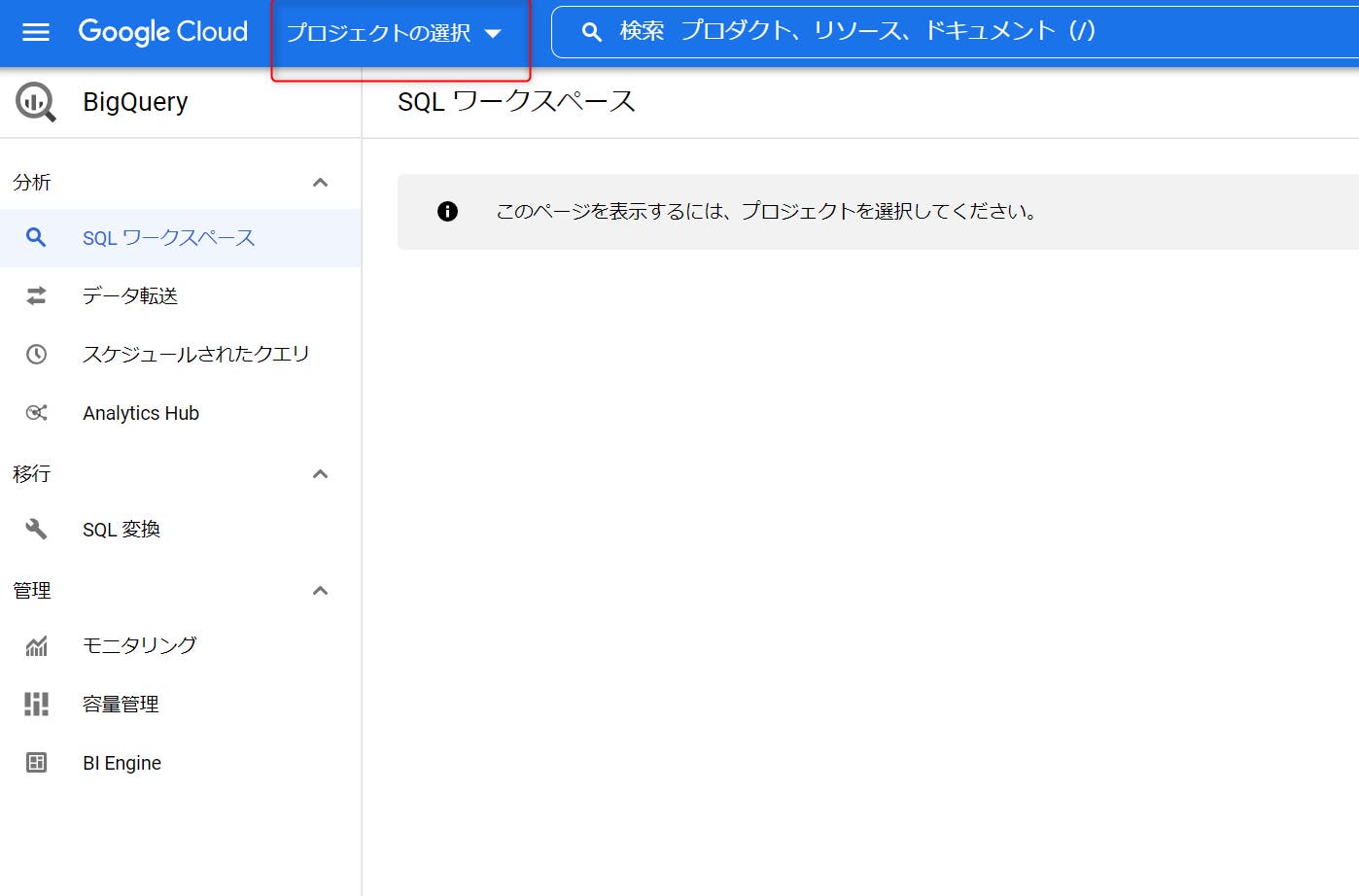
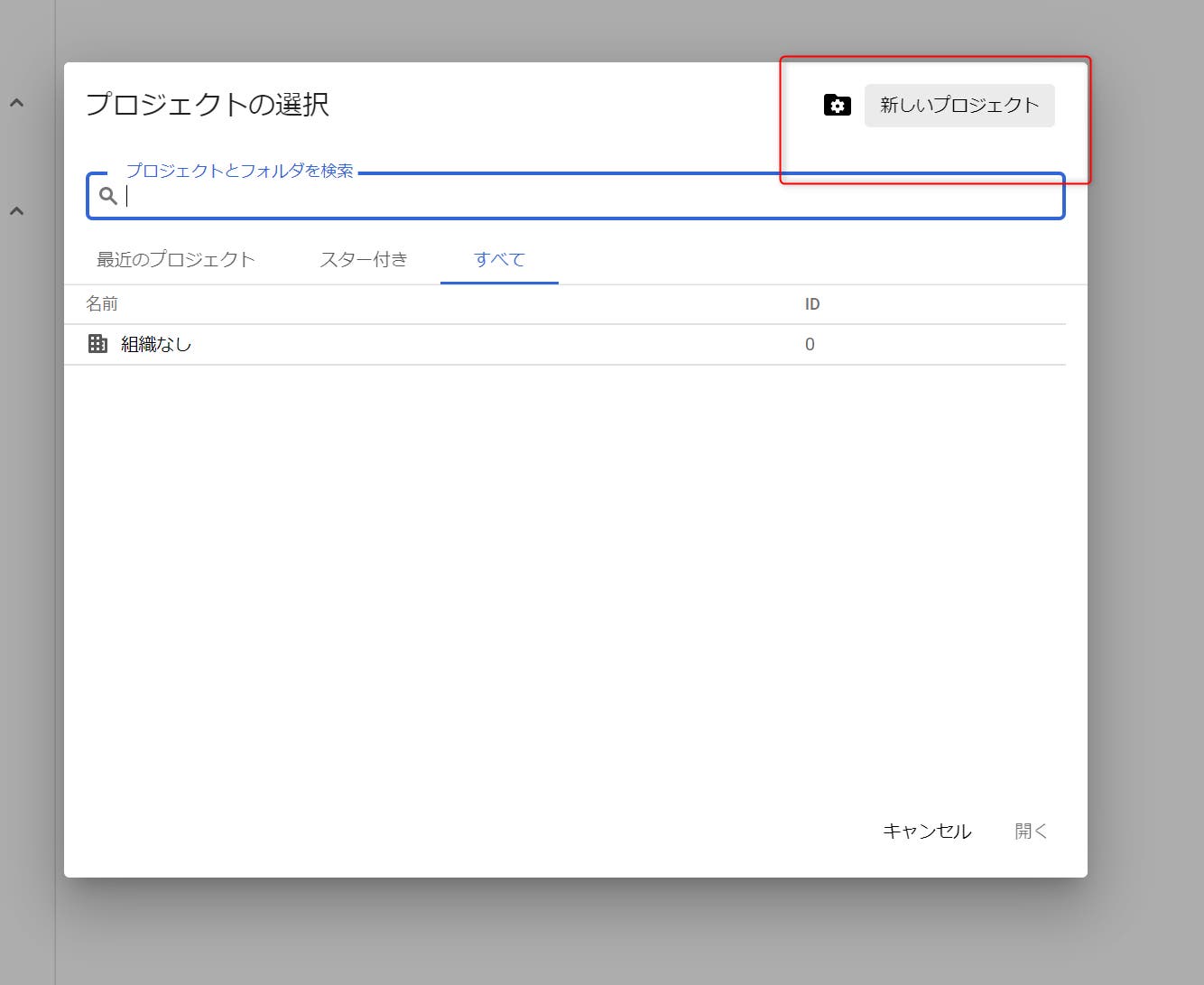
STEP 03:次に「プロジェクト」を作成します。「プロジェクト」は、GCPにおけるデータの最上位概念です。
STEP 04:任意のプロジェクト名を入力し、作成をクリックします。 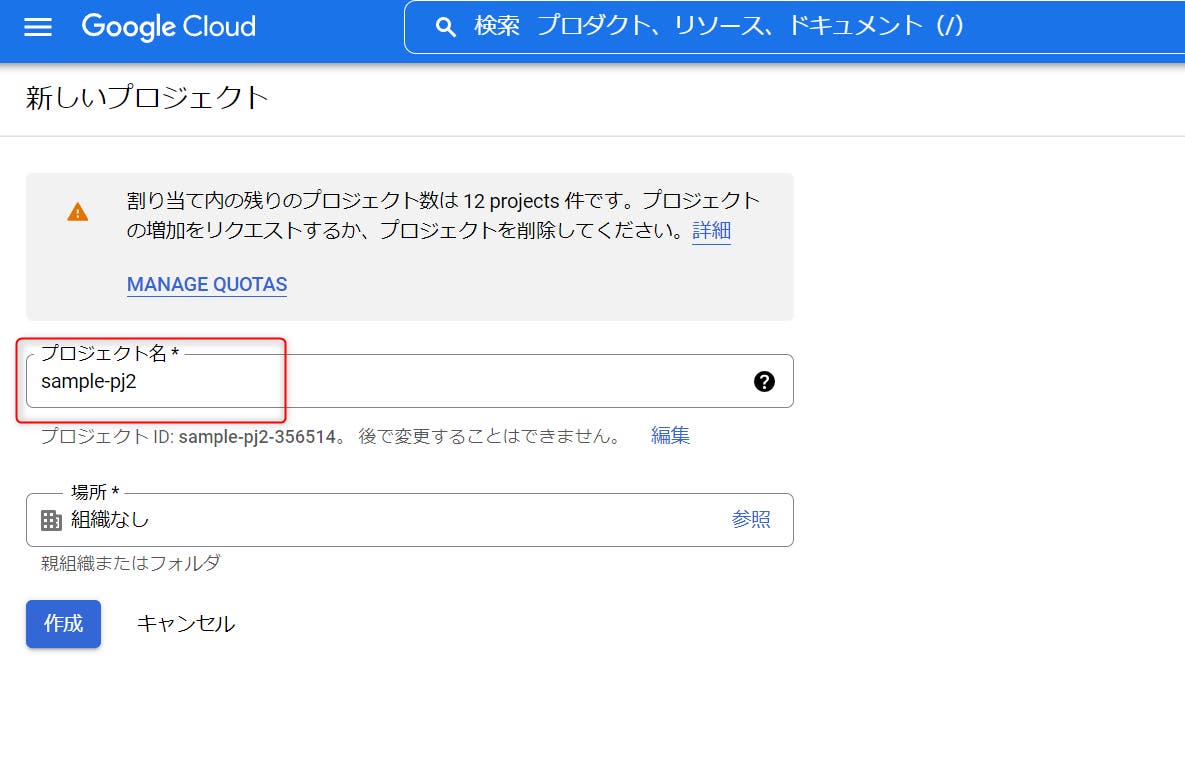
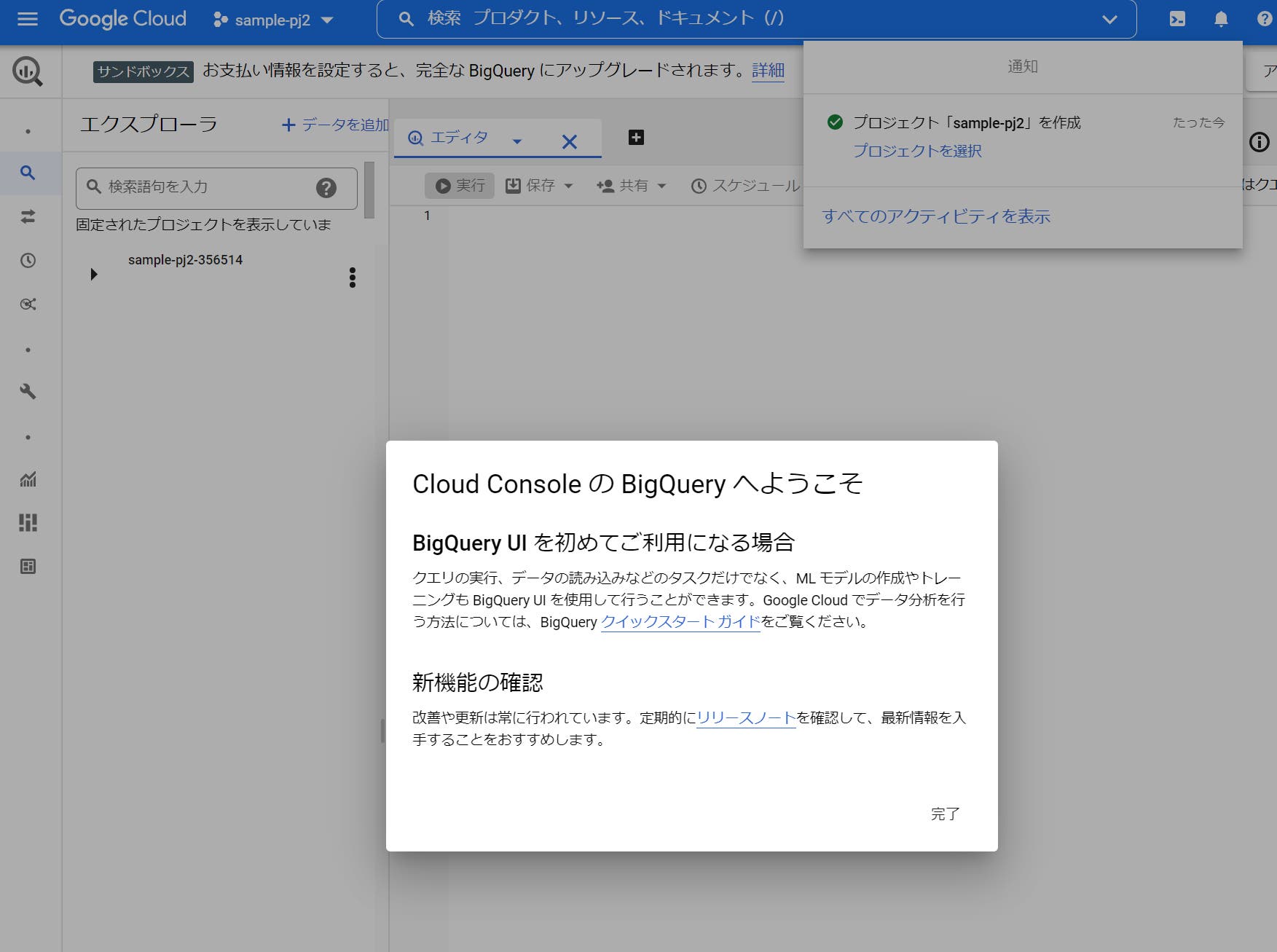
STEP 05:プロジェクト作成が成功すると、上図の完了画面が表示されます。 これで準備完了です。続いて、具体的なデータ分析手順に入ります。
セットアップが完了したら、続いて具体的な分析方法の解説に移ります。今回はデータセットの作成からSQLの実行までを紹介します。
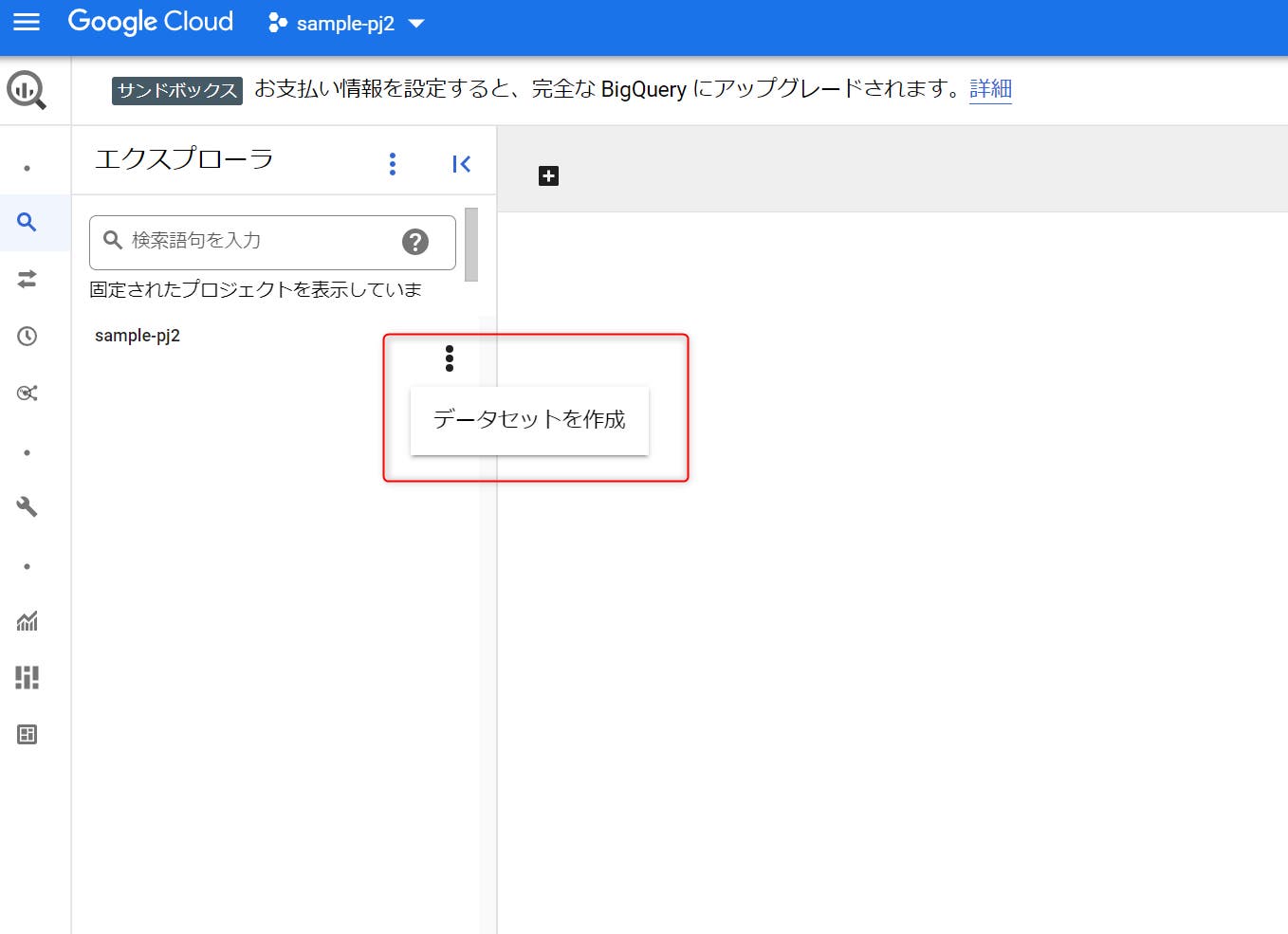
STEP 01:分析対象データをBigQueryに格納するため、まずは「データセット」を作成します。プロジェクトのメニュー(3つの点が縦に並んだマーク)を開き、「データセットの作成」をクリックします。
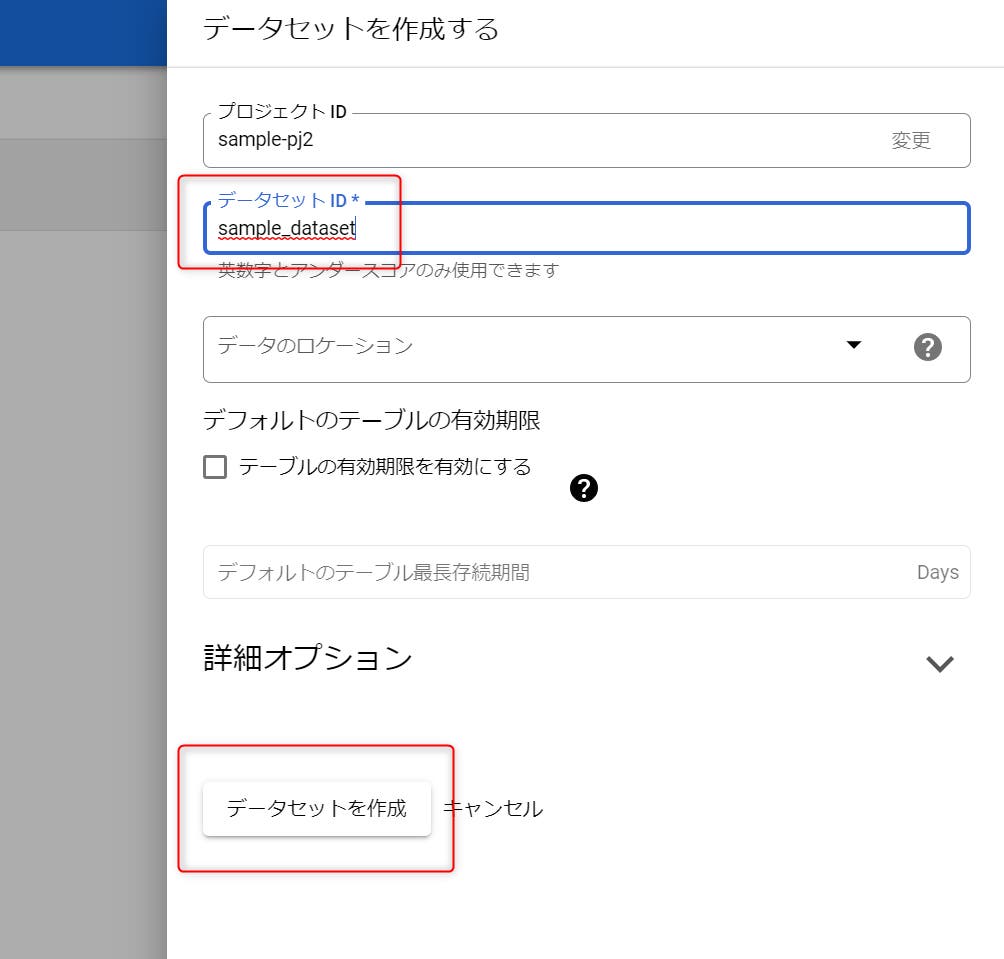
STEP 02:任意のデータセットIDを入力し、「データセットを作成」をクリックします。
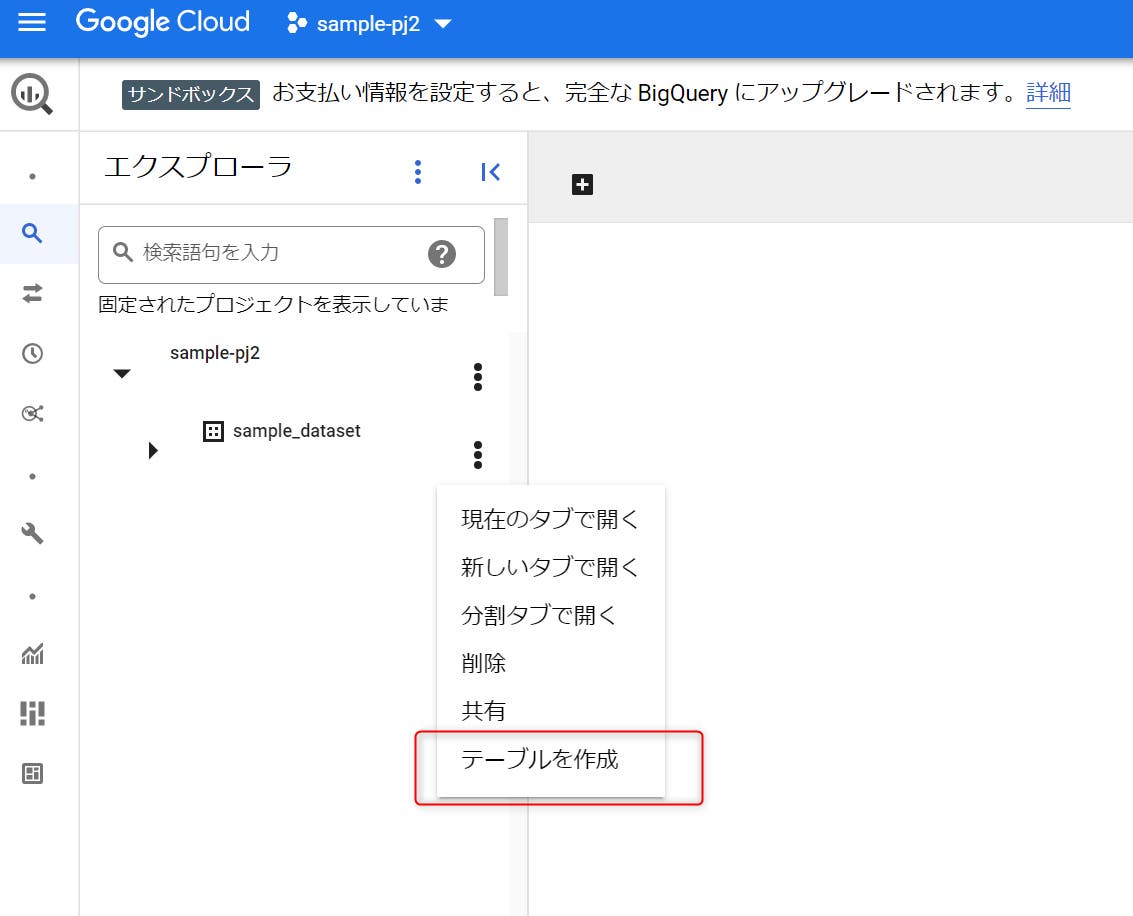
STEP 03:新規のデータセットが作成されました。続いて、データセットのメニューを開き、「テーブルを作成」をクリックします。
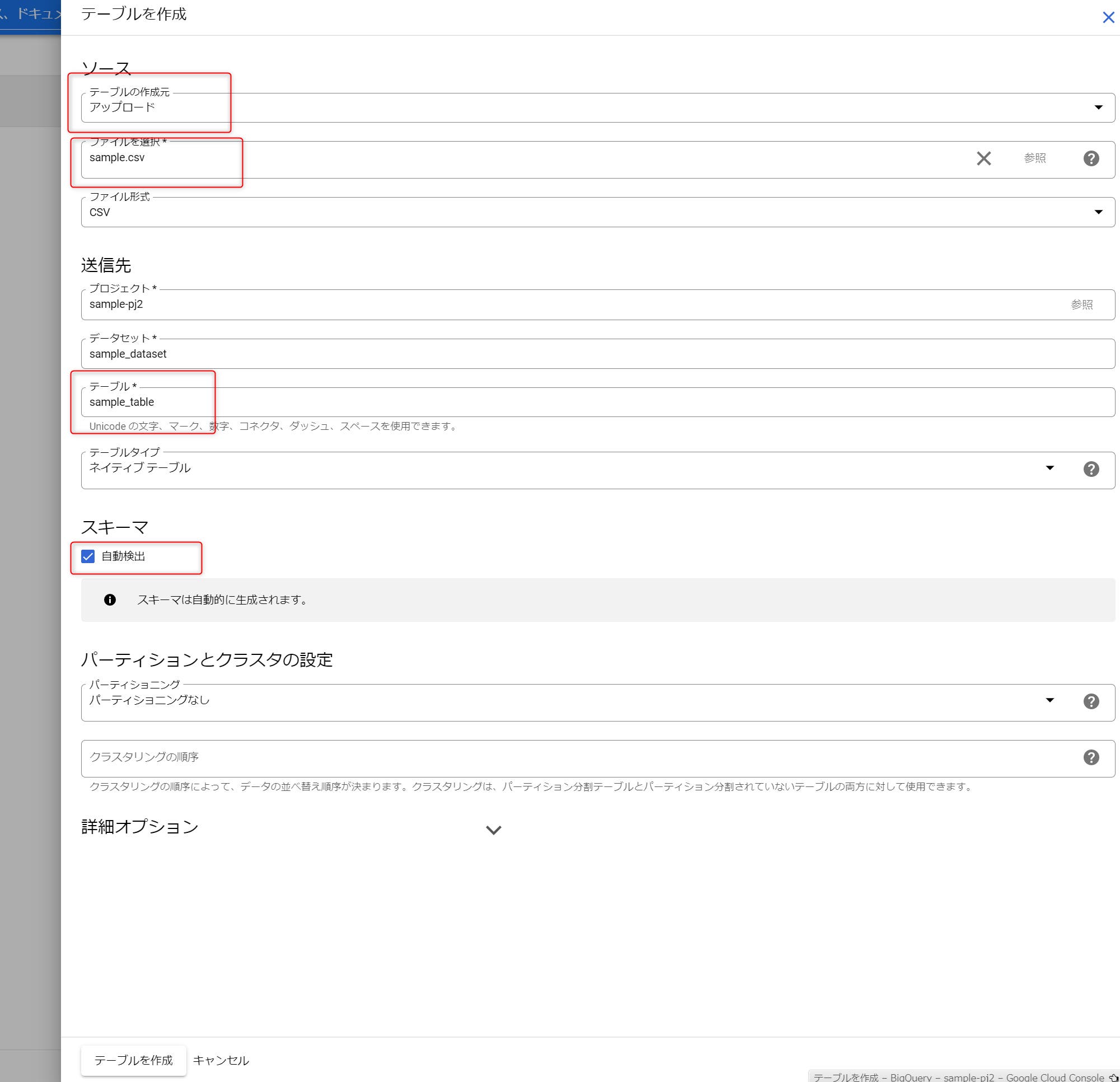
STEP 04:今回は一例として、手持ちのCSVファイルをアップロードしてみます。
このように設定し、「テーブルを作成」をクリックします。
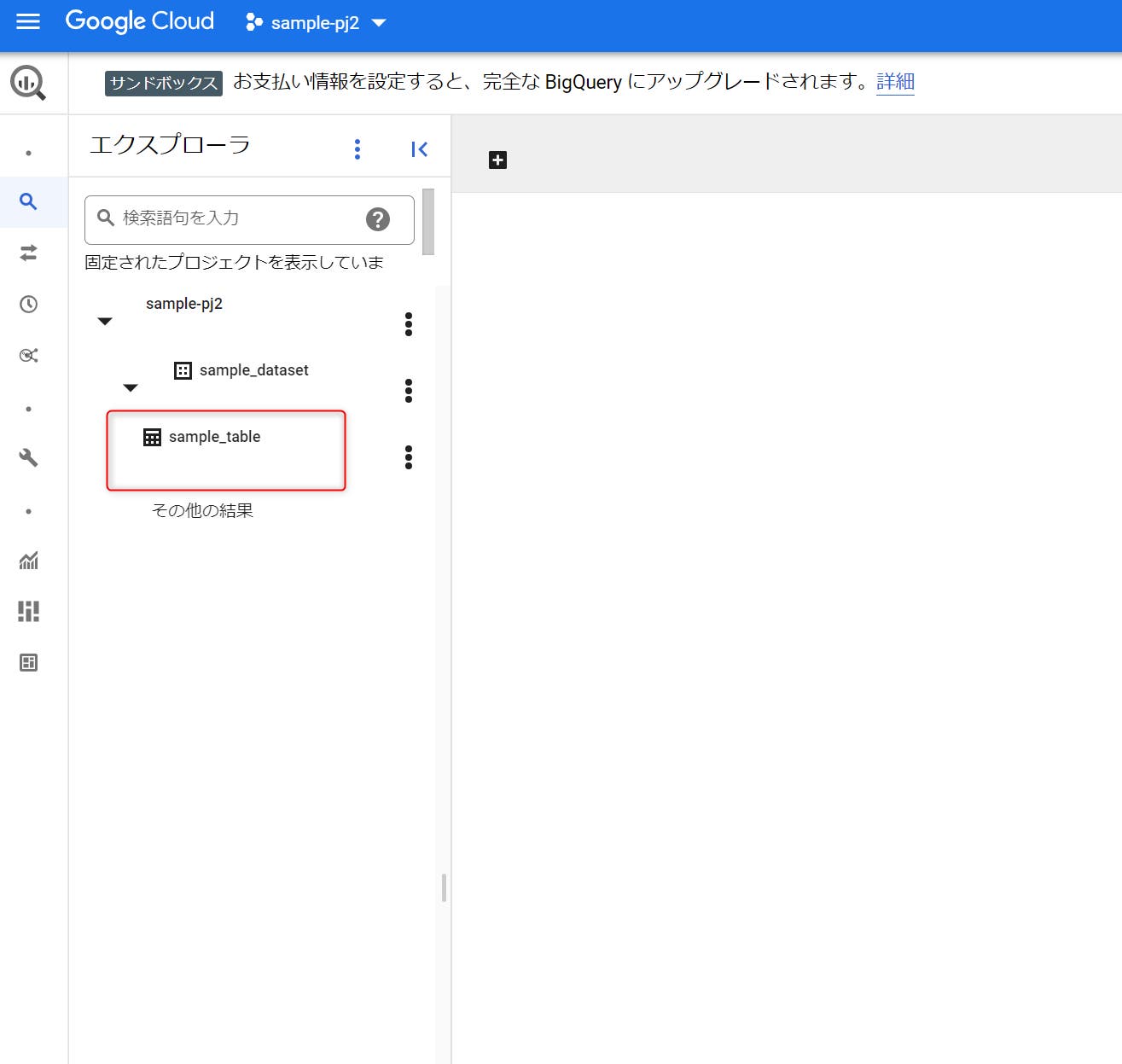
STEP 05:すると、図のように先ほど作成したテーブルが表示されていることが確認できます。あるいは、ローカルのCSVファイルをアップロードするのではなく、GoogleドライブのCSVファイルを読み込ませることも可能です。この場合、Googleドライブにおける「ファイルID」というものを取得する必要があります。
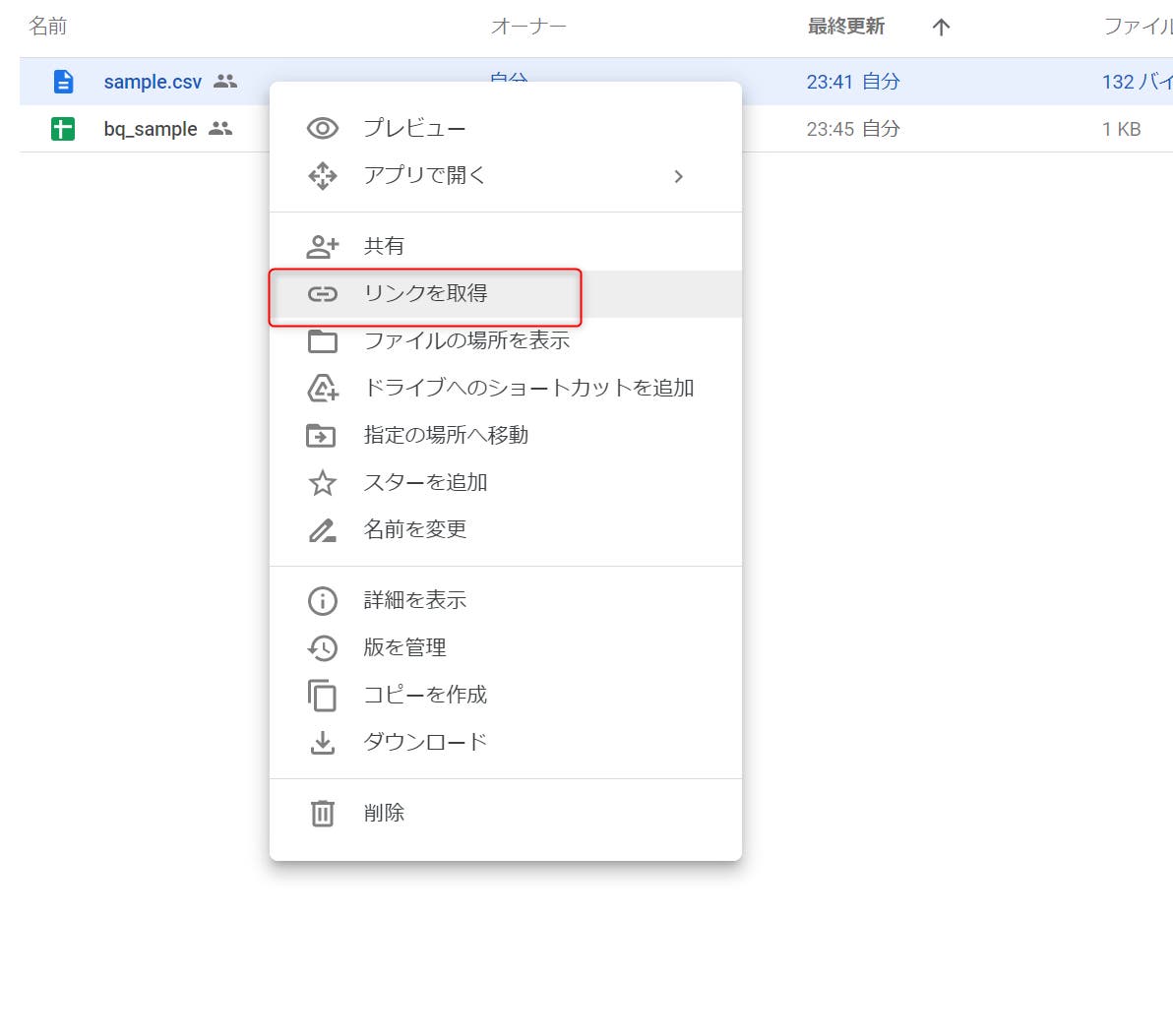
STEP 06:Googleドライブ上のファイルを右クリックして「リンクを取得」をクリックします。
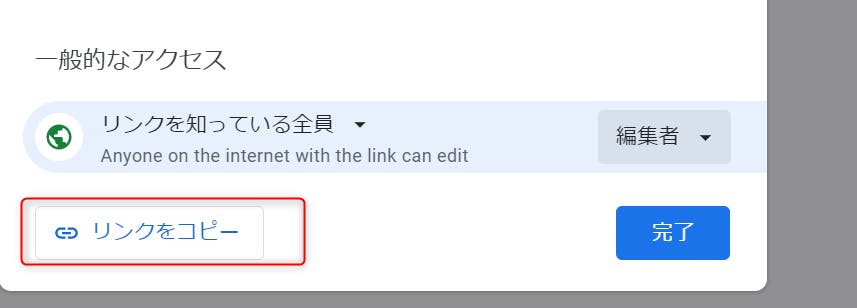
STEP 07:その後、開いたウィンドウの「リンクをコピー」をクリックします。 では、メモ帳を開き、たったいまコピーしたリンクを貼り付けてみましょう。
https://drive.google.com/file/d/XXX/view?usp=sharing
このようなURL形式になっているかと思います。この、XXXの部分が、ファイルIDとなります。 これを、
https://drive.google.com/open?id=XXX
の形に書き換えてください。これがBigQueryにCSVファイルを読み込ませるための識別子(URI)となります。
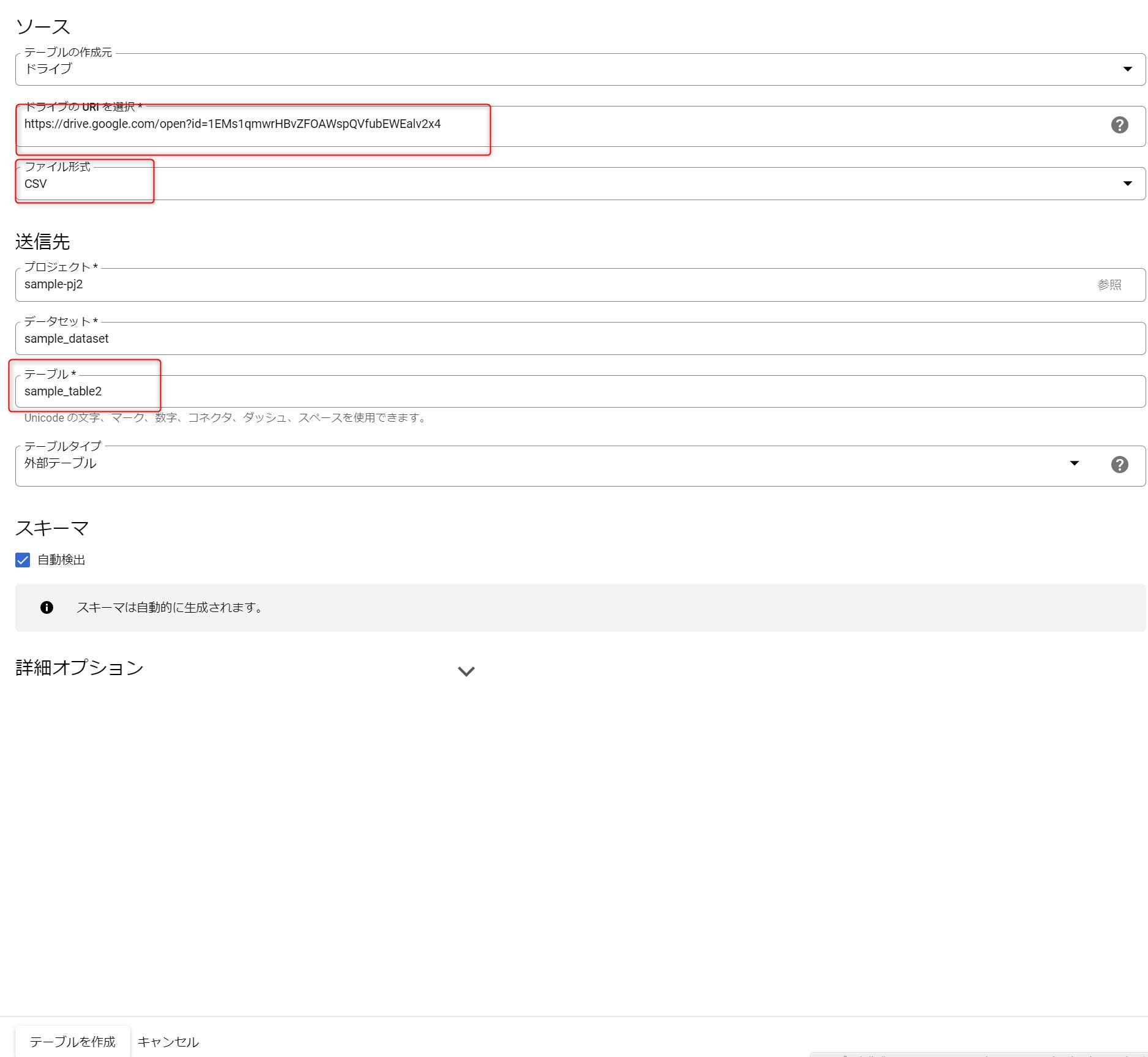
STEP 08:先ほどと同様の手順で「テーブルを作成」画面を開き、今度は入力内容を若干変更します。
このように設定し、「テーブルを作成」を入力すると、CSVの内容が読み込まれてテーブルが作成されます。 では、具体的にテーブルの中身を見てみましょう。
今回はテストデータとして、以下のような単純なCSVファイルを用意しました。

STEP 09:データが格納されたテーブルの中身を見るには、BigQueryのコンソールにて、SQL(データを取得するための命令文)の入力が必要となります。
select * from (データセット名).(テーブル名)
というSQLを入力し、実行ボタンをクリックしてみましょう。
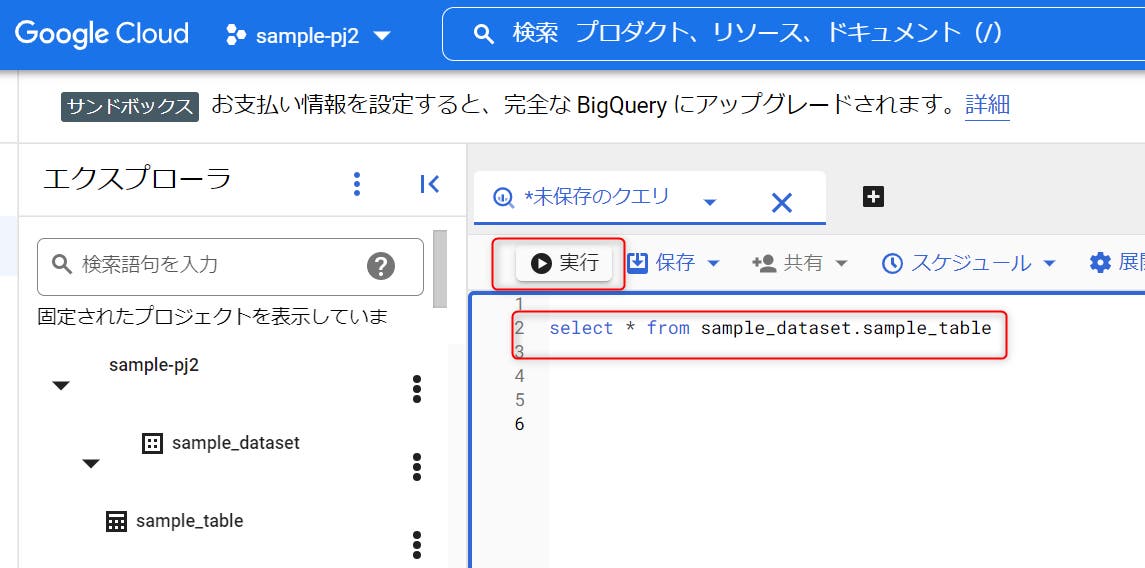
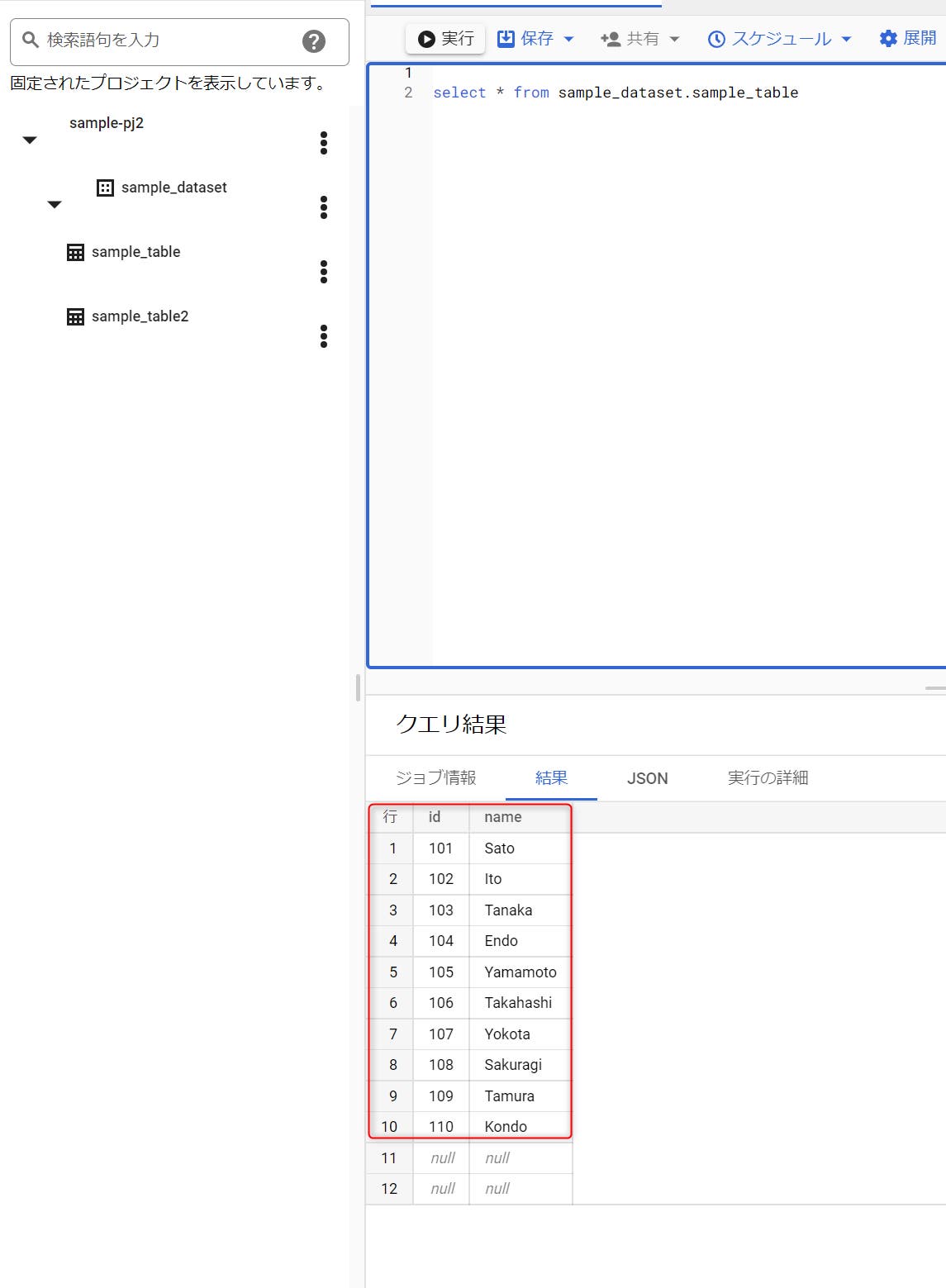
STEP 10:SQLを実行すると、上図のように実行結果が表示されます。 前述のCSVファイルと同じ内容のデータが格納されていることが分かります。
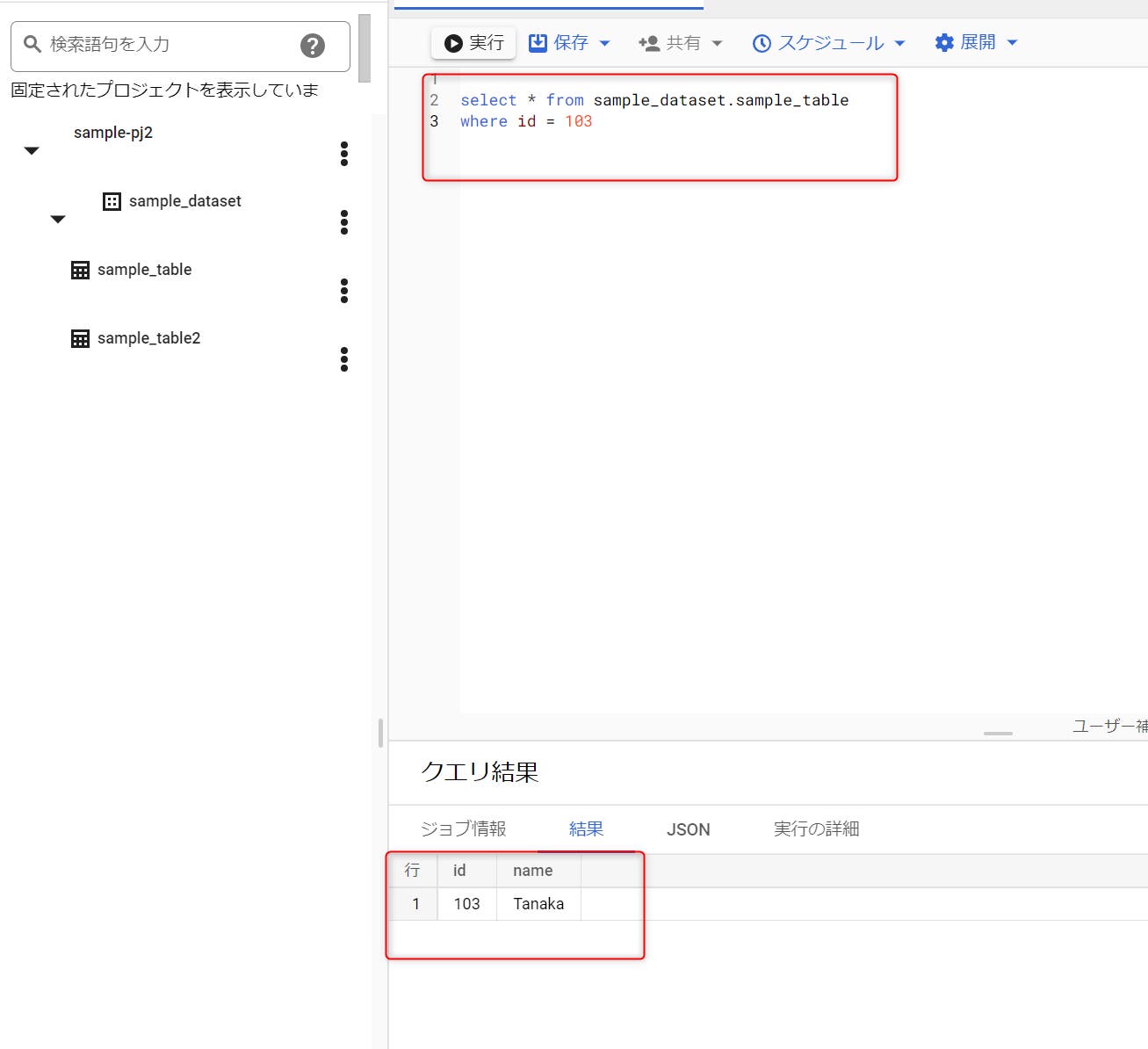
STEP 11:SQLには多数の構文があるため、全てを本稿でご紹介することはできませんが、よく使われるもののひとつがwhere句になります。これは、特定の条件でデータを絞り込みたいときに使われるものです。
例えば、idの値が103である行のみに絞り込みたいときは、上図のように、
where id=103
という一行を追加して実行します。
BigQueryとはどんなツールなのか、そしてデータ分析手法の基礎について解説しました。本稿の内容はBigQueryでできることのほんの一部でしかなく、BigQueryを使いこなせば、社内に散らばるあらゆるデータを統合・分析できると言っても過言ではありません。 これからの時代、データドリブンに意思決定しスピード感を持って前進していく企業が競争を勝ち残っていくと予想されます。ぜひ皆さんも、日々のマーケティング業務にBigQueryあるいは同等のデータウェアハウスを取り入れることを検討してみてください。
弊社の会社概要と、ケイパビリティのご紹介資料です。ご覧いただき、お気軽にお問い合わせください。
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。
share

Web広告
最終更新日:2025.02.13

マーケティング
最終更新日:2022.12.23

マーケティング
最終更新日:2022.12.23

SNSマーケティング
最終更新日:2026.06.22

マーケティング
最終更新日:2022.12.23

マーケティング
最終更新日:2022.12.23

SEO対策
最終更新日:2026.04.17

マーケティング
最終更新日:2022.12.23