
今更だけど、データ圧縮についてまとめてみたい
TECH
最終更新日:2022.12.23
![]()
更新日:2022.12.23

近年、色々なサイトで見られるようになった、”レコメンド”。
など、ECサイトだけでなくブログにまで存在し、サイトに訪問したユーザーに応じて、適した商品や記事をお勧めしてくれます。お勧めされた商品がふと気になり、なんとなくクリックしたら確かに良さそうな商品で思わず買ってしまった、そんな経験をした方も多いのではないでしょうか?
今回はそんな「レコメンド」に使われている、推薦アルゴリズムについて解説していきます。
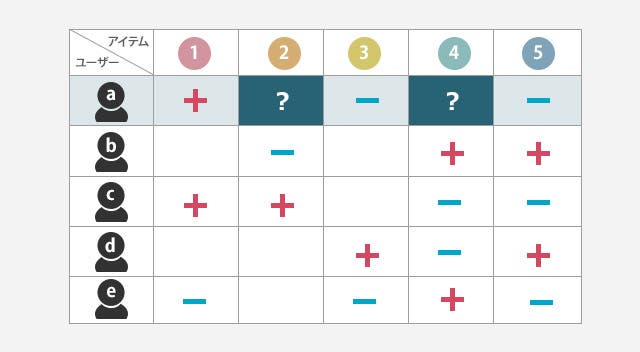
推薦アルゴリズムの基本は、ユーザー・アイテム間の履歴を行列の形で表現するところから始まります。要素が取りうる値は0/1や実数値、具体的な5段階の評価値まで様々な形です。(例:クリックした/していない、閲覧した/していない、高評価/低評価、など)
この行列のうち、値が埋まっている箇所については、ユーザーがアイテムについて何らかの行動を起こしたということであり、推薦アルゴリズムでは、値が埋まっていない箇所(未観測値)に対して、値を予測することになります。
その予測値を基に「この人はどんなアイテムを好みそうか」という傾向を見つけていきます。
[ユーザー・アイテム行列]
まず最初に説明するのは、非個人化推薦(Non-Personalized Recommender)と呼ばれる手法です。この方法はその名の通り、個人によらない推薦の方式です。
具体的には、
などの手法があります。
複雑なアルゴリズムを必要とせず、古典的な手法に見えますが、データによっては意外と高精度を叩き出す可能性があります。推薦システムを作ろうとした時、いきなり複雑なロジックを扱おうとするのではなく、こういった部分から始めて見るのも悪くはないと思います。
次に扱うのは、個人化推薦(Personalized Recommender)で、数式や機械学習を使った賢そうな手法の多くはこれに該当します。これは非個人化推薦の逆で、個人個人に最適化して商品を推薦するという方法です。
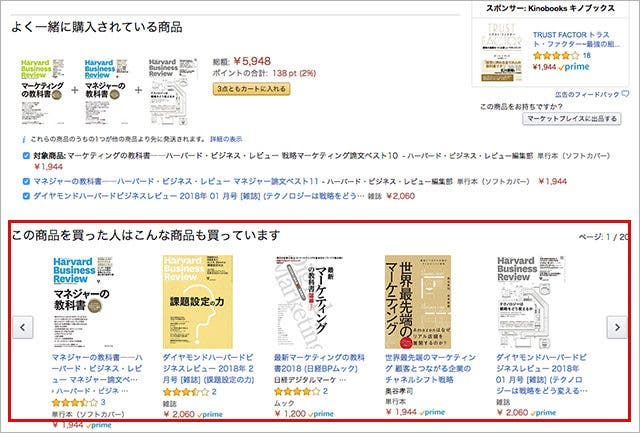
協調フィルタリング(Collaborative Filtering)も、個人化推薦の手法の一つで、Amazonの「この商品を買った人はこちらの商品も〜」で有名なものです。協調フィルタリングでは、ユーザー間の類似度もしくはアイテム間の類似度に基づいて、商品を推薦します。
どういうことかざっくり説明すると、サービスに訪れるユーザーのうち、AさんとBさんが好みの商品が似ているかどうかを計算し、似ているのであれば、「Aさんは購入したけどまだBさんはまだ購入していない商品」を、Bさんに推薦するというような方式です。具体的には、ユーザー・アイテム行列の各ペアに対して、類似度を計算し未観測値を予測します。
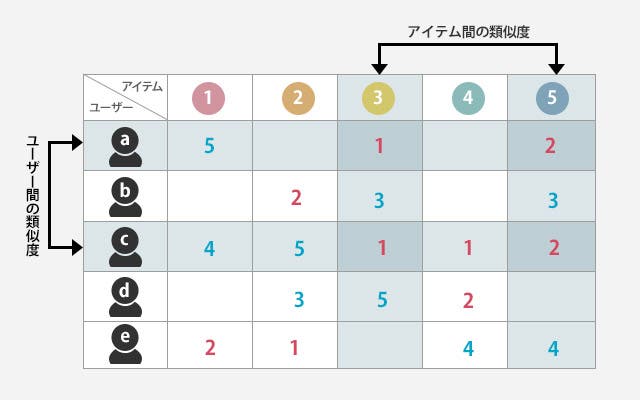
協調フィルタリングにおいて、ユーザー間の類似度とアイテム間の類似度だと、どちらを利用するのがよいのかということは度々議論されています。一般的に世の中のインターネットサービスは膨大なユーザーを抱えており、各ユーザーの趣味・嗜好は動的に変化します。その結果ユーザー間類似度は計算が非効率で、かつ頻繁な再計算が必要となります。
一方、アイテム数はユーザー数に比べると十分に少なく、それらの特徴はある程度変わることがありません。なので、ユーザー間の類似度よりもアイテム間の類似度のほうが現実的な選択と言えるでしょう。
ですが、サービスの規模や種類によっては、ユーザー間の類似度を利用した方が、精度が高まる場合ももちろん存在するので、再計算のコストなども加味した上で、自サービスに合っているものを選択していく必要があります。
協調フィルタリングは、「似たユーザーが買ったものを推薦する」というような形なので、非常に有効な方法ですが、実は以下のような問題点があります。
そこで、これらの問題をできるだけ解決し、「ユーザー・アイテム行列からできるだけ効率的に、より本質的なユーザの趣味・嗜好を抽出したい」というモチベーションから生まれた推薦手法が、次元削減に基づくものです。
次元削減では、ユーザー・アイテム行列を、「ユーザーに関する特徴が詰まった行列」と「アイテムに関する特徴が詰まった行列」に分解し、それら二つ(と重み)の掛け算によって新たな行列を作ります。
その新たな行列は元のユーザー・アイテム行列の近似となっていて、かつ、元の行列では未観測値だった箇所に対しても、何らか値が入っているため、その値を予測して使うことができます。
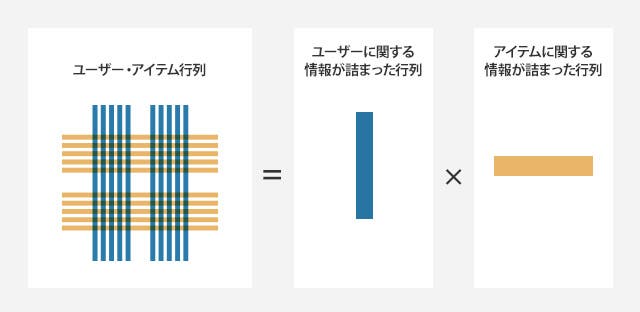
次元削減には、元行列の未観測値を0で補って計算する方法である特異値分解と呼ばれる手法や、観測した値のみを使って行列を分解するMatrix Factorizationという手法などがあります。
今回は、Webサービス上でよく見られる、レコメンドについて、よく使われるアルゴリズムをざっくり解説しました。この記事では、3つの手法を紹介しておりますが、「この手法が一番正しい!」「どんな事例でもこの手法が精度が出る!」といった手法は存在しません。
もしかしたら、個人化推薦で、一番人気のアイテムを全員に対して推薦するのが一番売上に貢献するかもしれません。他の機械学習と同様に、精度を出すためのトライアル&エラーを行い、精度だけでなく、計算コストとも相談した上で手法を選択する必要があります。
普段よく見かるようなものにも、裏では色々な手法が試され、技術が洗練されていっています。そういったものに、「これ、裏ではどんなロジックが動いているのだろう?」と疑問を持って調べて見ると、また違った観点で見ることができて興味深いです。この記事を機に、調べてみてはいかがでしょうか?
share

2017年新卒入社。JuicerやSEARCH WRITEなど自社プロダクトの機械学習分野の企画・開発、SEO分野の研究開発・知財化などに携わる。現在は全社的なデータ活用にも関わり、マーケティング自動化やデータ駆動化の技術支援やデータマネジメントも行う。脱出ゲームの生涯脱出率は5割を超える(2020年10月現在81戦41勝)。
TECH
最終更新日:2022.12.23
TECH
最終更新日:2024.03.12

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2023.05.01