
PySparkでDataframeを操作する
TECH
最終更新日:2022.12.23
![]()
更新日:2022.12.23

AWS GlueでSparkを実行した際にジョブの結果を監視、トラブルシューティングできるツールは無いものかと探したところウェブUIによって可視化することができる、Spark UIがありました。ローカルマシンでDockerでのSpark History Serverの起動や、見方などを簡単にご紹介します。
ローカルマシンにgitとDockerがインストールされており、使用できる状態という前提となります。
使用環境
| 機種 | MacBook Pro |
|---|---|
| OS | Catalina 10.15.7 |
| プロセッサ | 2.3 GHz デュアルコアIntel Core i5 |
| メモリ | 16GB |
| AWS Glue | 2.0 |
| Spark | 2.4 |
| 言語 | Scala |
AWSの公式ブログによると
Spark UIは、Glue ETL ジョブ実行のさまざまなステージを表すDirected Acyclic Graph (DAG(有向非循環グラフ)) をウェブインターフェイスによって可視化することができます。また、Spark SQL クエリプランを分析し、実行中や終了したSpark executorのイベントタイムラインを確認します。 Spark UIはGlue ETL ジョブおよび Glue 開発エンドポイントの両方で利用可能です。
このように記載されています。平たく言えば、ETLの実行結果がグラフなどで可視化されて、とても見やすくなっているということですね。
ジョブ単位でパフォーマンスを見たり、どのジョブの、どの処理で性能が出ていないのかなどチューニングする際の指標にもなります。
前述のように、Spark UIを利用することで、ジョブの実行結果を可視化することが出来ます。History Serverを起動すればアプリケーション一覧を見ることができ、アプリケーションごとにイベントタイムラインによるジョブのパフォーマンスやボトルネックの特定、デバッグを行うことができます。
また、アプリケーション単位でイベントログをエクスポートすることも可能となっており、AWSサポートへ問い合わせを行う際にメッセージと一緒にログファイルを添付し使用することができます。
AWSの方に直接お話を聞きましたが、AWS Glueを使用する際にはSpark UIの設定を有効にして使ってほしいとのことです。問い合わせを受ける側としてもイベントログがある方が詳細に調べることも解決までの時間短縮にもなるそうです。
Spark History Serverを起動する前に、まずはSpark UIを有効にする手順からご説明します。今回はAWSコンソールからSpark UIの設定を有効にする方法を記載しますが、CloudFormationなどからでも可能です。
手順は非常に簡単で、まずログの出力先であるS3バケットを用意します。もちろん既存のバケットを使用することも可能ですが、専用に作っておいたほうが後の管理がしやすいでしょう。
S3にログの出力先であるバケットを用意したら、次にAWS Glueの方で設定を行います。ジョブの追加、或いは既存ジョブの編集から設定が可能で「モニタリングオプション」を開きSpark UIのチェックボックスにチェックを入れます。
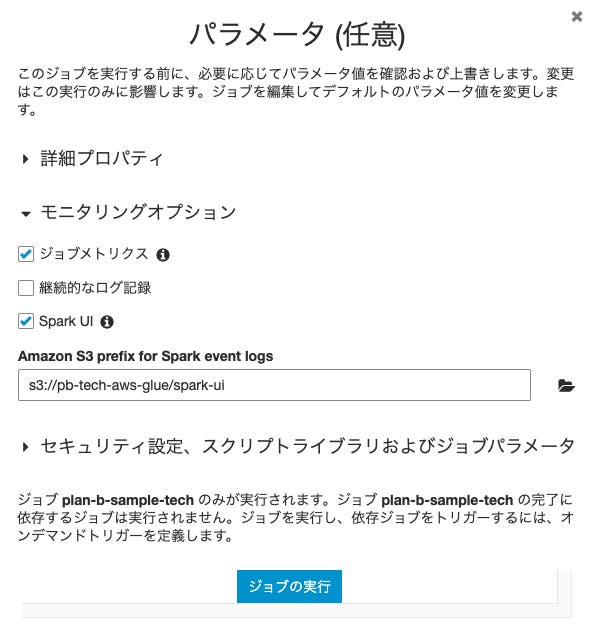
すると、「Amazon S3 prefix for Spark event logs」とログの出力先パスを入力するテキストフィールドが現れます。ここに先程用意したS3のパスを入力し保存します。
たったこれだけでSpark UIを使用するための設定が完了です。
それではSpark History Serverを起動してみましょう。Spark History Serverを起動するにはDockerを使用します。
まず、指定のGitHubリポジトリからDockerイメージをクローンします。
|
1 |
$ git clone aws-samples/aws-glue-samples |
次に特定のディレクトリへ移動し、以下のようにビルドを行います。
|
1 2 |
$ cd aws-glue-samples/utilities/Spark_UI/glue-1_0-2_0 $ docker build -t glue/sparkui:latest . |
ビルドが終わったらコンテナを起動します。ログディレクトリ(-Dspark.history.fs.logDirectory)には先程用意したS3のパスを指定し、アクセスキー(-Dspark.hadoop.fs.s3a.access.key)、シークレットキー(-Dspark.hadoop.fs.s3a.secret.key)にはS3へのリード権限がアタッチされたものを使用します。
|
1 |
$ docker run -itd -e SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.fs.logDirectory=s3a://path_to_eventlog -Dspark.hadoop.fs.s3a.access.key=AWS_ACCESS_KEY_ID -Dspark.hadoop.fs.s3a.secret.key=AWS_SECRET_ACCESS_KEY" -p 18080:18080 glue/sparkui:latest "/opt/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer" |
エラー無くコマンドが実行されればバックグラウンドでコンテナが起動しブラウザでSpark History Serverを閲覧することができます。
それでは先程Dockerで立ち上げたコンテナをブラウザから覗いてみましょう。
コンテナが起動したらブラウザを開きアドレスバーに http://localhost:18080/ と入力しアクセスします。
アクセスするとトップページと他Jobs,Stages,Storage,Environment,Executors,SQLなどのメニューが表示されます。更に公式ではStructured Streaming,Streaming,JDBC/ODBC Serverなどのタブについても説明がありますが、本記事ではJobs,Stages,Storage,Environment,Executorsまでを紹介しています。
アクセスすると実行が完了したアプリケーションの一覧が表示されます。(実行が完了したアプリケーションの一覧と書きましたが、少なくとも一度以上Glue Jobを実行しログが出力されていることが必要です)
一覧の下部にある「Show incomplete applications」または「Back to completed applications」をクリックすることで、実行中のアプリケーション、実行完了のアプリケーション一覧を切り替えて表示することが可能です。
また、この画面からイベントログをダウンロードすることも可能で、アプリケーション単位でログの詳細を見ることができます。

ここで言うアプリケーションとはAWS Glueのコンソールからみたジョブの実行単位で実行 IDがついているものになります。
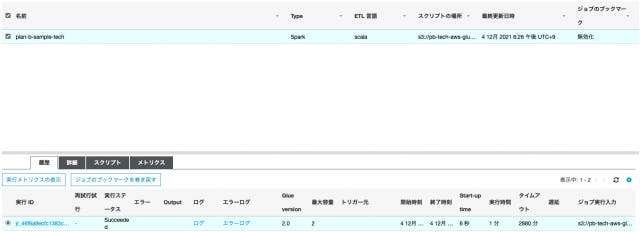
この実行 IDをHistory Serverの方で検索すると、そのアプリケーションの実行状況について詳しく見ることができ、App Idはリンクになっているので、そのアプリケーションのJob一覧へ遷移します。
Jobsタブでは、アプリケーション全てのJob一覧を表示しており、概要、詳細などのページを表示します。概要ではジョブのステータスや、持続時間、進行状況、イベントタイムラインを見ることができるようになっています。イベントタイムラインではJobの実行や、Executorの追加を見ることができます。
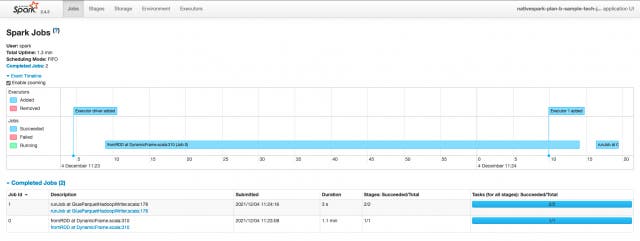
Job Id毎にあるDescriptionのリンク先には、そのJobについての詳細、Stage一覧を見ることができ、イベントタイムラインやDAGの表示もあるので、より視覚的に処理の状況を知ることができます。

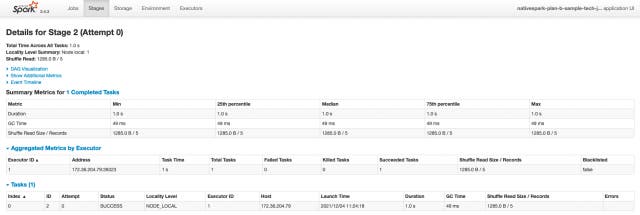
Stagesタブでは、アプリケーションが持つジョブ全体のステージ、現在の状態を示す概要を表示します。
画像では完了ステータスのもののみ表示されておりますが、ログが溜まっている状態であればアクティブ、保留、完了、スキップ、失敗など各ステータスごとのステージが表示されます。
概要にあるリンクから詳細へ遷移すれば、すべてのタスクの合計時間やシャッフル、DAGなどの情報が閲覧できます。ステージが多いと実行コストが高くチューニングをする際の重要な指標にもなります。
Storageタブでは、RDDとデータフレームが表示されます。
データフレームについては存在する場合にのみ表示されます。概要にはストレージレベルやサイズ、RDDのパーティションなどが表示され、詳細へ遷移するとRDD、データフレーム内の全てのパーティションのサイズやexecutorの使用などを見ることが可能です。
Environmentタブでは、JVM、Spark、システムプロパティを含む様々な環境変数と構成変数が表示されます。
プロパティが正しく設定されているか、クラスパスなどの競合を解決する際に見ることはありますが、チューニングやデバッグを行う上で、そこまで多くを確認するようなページではないように思います。
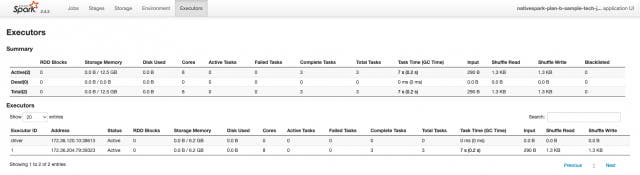
Executorsタブでは、メモリやディスクの使用状況や、タスクやシャッフルの情報を見ることが出来ます。このページではJVMのスレッドダンプども表示されるため性能分析にも非常に役立つと言えるでしょう。
AWS Glueに限らずこういったSparkの可視化ツールはありますが、AWS GlueでSparkを使用する際にはSpark UIを有効にし各ジョブの実行状態を追えるようにしておくと、後のチューニングやデバッグなどに大変便利です。
導入前にはなんとなく時間のかかる処理は一律G.2Xを使用したり、多めにDPUを投入したりしていましたが、Spark UIを導入してみて、実際にはメモリの余裕が十分以上にあることがわかり、かなりオーバースペックでコストの削減余地があることがわかりました。
また、Stagesをみて負荷や処理コストの掛かっている箇所を特定し、プログラムの組み方、主にデータフレーム内での処理を改善するなどし飛躍的に処理速度が改善したといったこともありました。
実際に触ってみなければわからない点も多々あるかと思いますが、手軽に導入できるので是非試してみてください。
share

2010年08月PLAN-B中途入社。社内基幹システムの開発・運用を担当し、その後、BtoC向け新規サービス立ち上げのプロジェクトリーダーとして開発に従事。自社プロダクトのバックエンド開発を経験した後、現在は受託チームとして開発を担当している。データベースが好きな1児のパパ。
TECH
最終更新日:2022.12.23

TECH
最終更新日:2023.05.09

TECH
最終更新日:2022.12.23

Webサイト制作
最終更新日:2023.12.12

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23
TECH
最終更新日:2024.03.12

TECH
最終更新日:2023.05.09