
今更だけど、データ圧縮についてまとめてみたい
TECH
最終更新日:2022.12.23
![]()
更新日:2024.03.14

PLAN-Bシステム開発本部の廣田と申します。前職まではSIerでエンジニアとして開発をしていました。PLAN-Bには入社して1年ほど経ち、現在はRevenue Baseという新規プロダクトの開発チームのチームリーダーをしています。新卒からずっとSIerで働いてきた私の初の自社プロダクト開発ということで、発見と学びの多い1年でした。その中から今回は、プロダクト運用についての学びについて記します。自社プロダクト開発・運用にご興味のある方や、手作業のプロダクト運用に苦労されている方の参考になれば幸いです。
自社プロダクト開発を行うPLAN-Bで、まず新鮮だったことは「プロダクトに関わることはすべて自社でやる」ということでした。
SIer時代は「開発」がメインでした。同じシステムを継続して保守する業務もありましたが、あくまでそれは保守「開発」でした。私がRevenue Baseチームに入ったタイミングは、価値を創出するために新規開発に集中している時期であり、運用フェーズについても0からのスタートであり私にとっては初めてのチャレンジとなりました。
そのため、新規開発にリソースを投入しながらも「限られたリソースでサービスを安定的に供給するためにどのように運用すべきか?」が課題となりました。
「プロダクト運用」を分解すると、以下のようになると考えています。
今回はプロダクトモニタリングでRevenue Baseチームが取り組んだことについて記載します。
モニタリングの仕組みを作るにあたって、モニタリングしたいものは多岐に渡りました。ただ、新規開発も進めなければならない状況であったため、洗い出したタスクに優先度をつけて対応を決定しました。グルーピングは大きく分けて3つです。
すべてモニタリングしたいところですが、新規開発も進めなければなりません。
まずは、2のトレーシングまでをモニタリングの最低ラインとして仕組みの構築を進めました。
まず、モニタリングの中心に、「Grafana」というオープンソースのデータ視覚化ツールを据えました。
Grafanaでは様々なデータソースからデータを集約して、視覚的にダッシュボードで表示ができます。また、アラートを設定することで集約したデータからリアルタイムでシステムの異常な状態を通知することができます。
Revenue Baseには以下の特徴があります。
AWS以外で利用している外部サービスも多くあったため、AWS内のデータモニタリングサービスであるCloudWatchでモニタリングするのではなく、すべての情報をGrafanaに集約することにしました。そうすることで、複数サービスにアクセスすることなくプロダクトを監視できることができます。また、開発チームメンバーには、最初からすべての外部サービスのアクセス権が付与されないケースもあります。そのようなケースでも、Grafanaにアクセスすればモニタリングのために必要な情報を取得できプロダクトの状態を知ることができます。
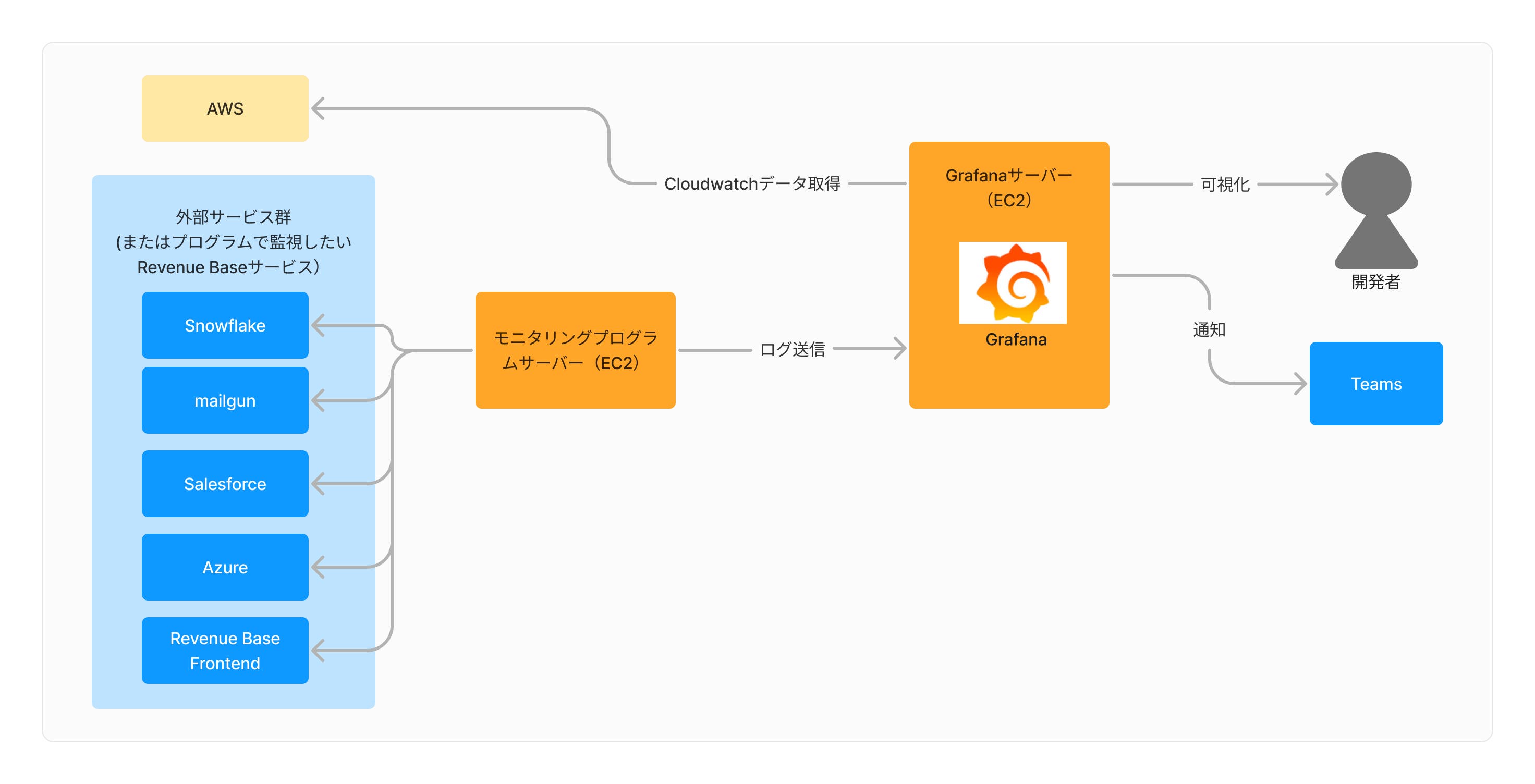
図のように外部サービスの監視を、AWS EC2に集約することで、メンテナンス工数が最小限になるように意識しました。また、各サービスを監視するためのプログラムは、1つのサービス監視で50行程度の簡素なPythonプログラムにしました。そうすることで、ジュニアクラスのエンジニアでも容易にメンテナンスできる状態を目指しました。EC2に集約することで、もしAWS以外のクラウドサービスに移行することになった場合に、比較的容易に移行できることもメリットだと考えています。
ここで外部サービスのモニタリングの一例を説明します。Revenue Baseではデータ分析のために「Snowflake」というクラウドベースのデータウェアハウスプラットフォームを使用しています。
Snowflakeの監視は以下のような流れです。
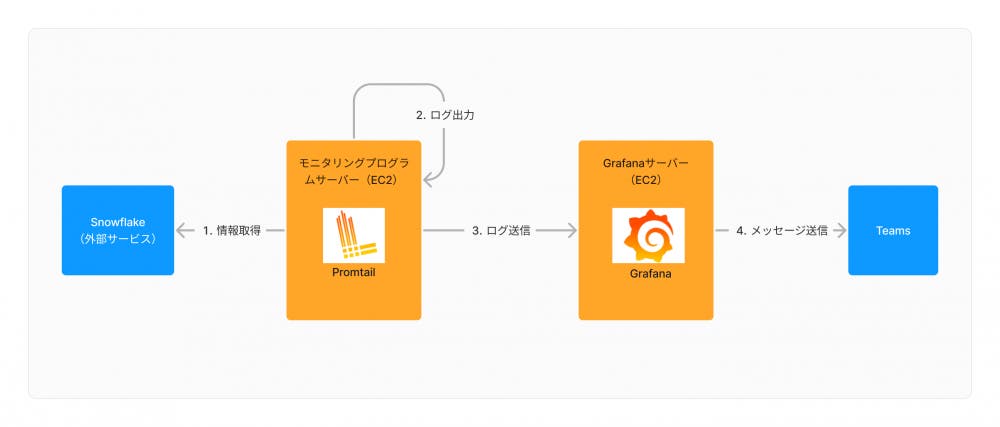
これにより、エンジニアはSnowflakeを日々手作業で監視することなくエラーが発生したときのみ対応すれば良くなります。
2023年の年末、長期休暇の際に実際にこの仕組みに頼って過ごしてみました。その結果、予期せぬトラブル通知はなく安心して年末年始を過ごすことができました。もしこの仕組みが無ければ、休日出勤をしてモニタリング手作業を行う必要がありました。そのため、休日出勤に伴う工数が省けたことはプロジェクトチームにとって大きな利点でした。なにより、「もしかするとプロダクトに問題が発生しているかもしれない」という心配をせずに、ゆっくりと休日を過ごせたことが最大のメリットでした。
デメリットとしては、その後の年明けのプロダクトの仕様変更により、想定外のモニタリングプログラムのメンテナンス工数が発生してしまったことです。具体的には、ログイン機能のモニタリングで、ログイン直後の画面情報で検証をしていましたが、ログイン直後に表示する画面が変わったため、検証方法を変更する必要が発生しました。
持続的でコストパフォーマンスの高いモニタリングをするには、先を見通してプログラムを組む能力が必要だと痛感しました。
基本的に、運用作業ではお客様へ直接的な価値を提供することはできません。当たり前の状態を作るだけで驚きや感動には繋げられないからです。私はRevenue Baseチームでの運用業務やモニタリングの仕組み構築を通して、「運用はすべてを自動かつメンテナンス不要にして、新規開発など価値を生む作業に時間を投下できること」が運用として目指す姿だと感じました。モニタリングプログラムを作ることでさえ、メンテナンスが発生する可能性があることを考えると、「本当にプログラムが必要か?」という観点も必要だと思います。
まだまだプロダクト運用は人力の部分は存在します。これは運用フェーズに対する私自身の知識・経験の浅さも一因だと考えています。
Revenue Baseはこれから本格的に利用されてプロダクトとして成長していくフェーズです。人力の運用が原因でプロダクトの成長を鈍化させてしまうことが無いよう、チームメンバーと共に成長し、プロダクト運用業務を目指す姿に近づけていきたいです。
share

2022年12月にPLAN-Bに入社。入社3ヶ月で新規プロダクト「Revenue Base」の開発リーダーとしてJoin。新卒から積み重ねてきたエンジニアとしての経験を活かし、「できることはすべてやる」をモットーにプロダクトの成功に向けて日々全力を尽くしている。ビール好きが高じて社内でのニックネームは「IPAさん」
TECH
最終更新日:2022.12.23

TECH
最終更新日:2023.05.09
TECH
最終更新日:2024.03.12

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23

TECH
最終更新日:2022.12.23